Abstract
In recent years, statistical methods have been widely used to analyze various aspects of language. More specifically, semantic analysis has been used to represent words, sentences, documents and other units in some form which conveys their meaning usefully. In this review, I propose to examine various unsupervised and data driven semantic models. The models presented are latent semantic analysis (LSA), probabilistic latent semantic analysis (PLSA), latent dirichlet allocation (LDA), probabilistic content models and term frequency–inverse document frequency (tf-idf).
These models are empirically based rather than motivated by annotation or human intervention. Additionally, the models are constructed on a text corpus. A common feature that these models share is that they are applied to longer length passages from paragraph length (several sentences) to document length (multiple paragraphs). A comparison of the models will be given along with their strengths, weaknesses and their intended application. Though these approaches are intended for longer length passages, I will also discuss their feasibility for use in analyzing shorter length passages of several sentences or less.
Introduction
Statistics in the modern world has immense validity and the developments in the field have enduring effect on related sectors. In recent years, statistical methods have become greatly popular and these are often widely used to analyze various aspects of language. More specifically, semantic analysis has been used to represent words, sentences, documents and other units in some form which conveys their meaning usefully. Semantic analysis is the most widely used statistical method in relation to language and its analysis.
An examination of the current literature in relation to the semantic analysis can bring about the most essential results which will categorically explain the importance of methods of the semantic analysis. Therefore, the purpose of this research paper has been to make an original survey in which the existing works relating to the topic are summarized and critiqued. The role of such a critical review of the existing researches in the area is often specified.
Therefore, this paper aims at a literature review of the most fundamental works relating to semantic analysis and the review will examine various unsupervised and data driven semantic models. It is also important to specify that the models presented in the review includes Latent Semantic Analysis (LSA), Probabilistic Latent Semantic Analysis (pLSA), Latent Dirichlet Allocation (LDA), Probabilistic Content Models and term frequency–inverse document frequency (tf-idf). Significantly, these models are empirically based rather than motivated by annotation or human intervention. In addition, the models are constructed on a text corpus.
One of the most important common features of these models is that they are applied to longer length passages from paragraph length (several sentences) to document length (multiple paragraphs). The significance of the comparative analysis of the models is often specified and this paper will aim at such a comparison along with an analysis of the various strengths, weaknesses, and intended application of these models. In this paper, the analysis covers the viability study of these methods at the level of longer length passages as well as at the level of shorter length passages of several sentences or less.
Aims of the study
The most important aim of this research paper is to make an original as well as functional survey of the existing literature with regard to semantic analysis approaches in which the significant works will be summarized and critiqued. It is also relatable that the report does not involve an original research in the area. Rather, the paper aims at critical analysis of the existing literature which will result in an effective evaluation of the semantic analysis methods. The emphasis of the paper, in other words, has been on providing a deep and comprehensive insight into high-quality research that exists on a scientific topic. Therefore, this study concentrates on the researches relating to the specific topic of semantic analysis and an investigation of the major weaknesses and gaps in the published work.
Literature Review
An introduction to the scientific articles reviewed and their main arguments
In this comparative analysis, it is of paramount consideration that statistical methods are most widely used in recent years. That is to say, statistical methods have been widely used, in recent years, to analyze different aspects of language. Specifically, the value of semantic analysis in the representation of words, sentences, documents and other units has often been stressed. This review examines various unsupervised and data driven semantic models including Latent Semantic Analysis (LSA), Probabilistic Latent Semantic Analysis (pLSA), Latent Dirichlet Allocation (LDA), Probabilistic Content Models, and term frequency–inverse document frequency (tf-idf) etc.
An essential quality of these models is that they are empirically based rather than motivated by annotation or human intervention, and they are also constructed on a text corpus. In the comparative study of these models, it is significant to realize that they, in common, are applied to longer length passages from paragraph length, which runs to several sentences, to document length, which may cover multiple paragraphs. This literature review also is useful in an understanding of the most significant strengths, weaknesses and the intended application of the semantic analysis methods.
In the recent years, the semantic capacity of the individuals increases at a fast pace and the reasons for this type of excessive learning have been explained by several intellectuals. The explanation of the mystery of excessive learning by Plato et al has pertinent value in an understanding of semantic analysis. In this background, it is important to have an analysis of how people acquire great amount of knowledge with the use of the little information they possess. Considered as a relevant problem, the question takes various forms which are of critical in this comparative analysis.
Thomas K Landauer and Susan T Dumais in their article, “A Solution to Plato’s Problem: The Latent Semantic Analysis Theory of Acquisition, Induction and Representation of Knowledge” deal with the mystery of excessive learning and come up with an innovative way of explain the factor. Accordingly, this factor can be effectively explained with the use of some simple notion, i.e. in certain areas of knowledge there are many weak interrelations and these can deeply amplify learning by a process of inference, if they are accurately used.
They also suggest that “a very simple mechanism of induction, the choice of the correct dimensionality in which to represent similarity between objects and events, can sometimes, in particular in learning about the similarity of the meanings of words, produce sufficient enhancement of knowledge to bridge the gap between the information available in local contiguity and what people know after large amounts of experience.” (Landauer & Dumais, 1997). The paper specifically explains the utility of latent semantic analysis (LSA) in stimulating the excessive learning and other psycholinguistic phenomena.
Significantly, latent semantic analysis (LSA) may be comprehended as an innovative general theory of acquired similarity and knowledge representation. In their article, Landauer and Dumais make it clear that the latent semantic analysis gained knowledge about the full vocabulary of English at an analogous rate to schoolchildren by way of persuading global knowledge circuitously from local co-occurrence data in a large body of representative text.
Latent semantic analysis, they conclude, “uses no prior linguistic or perceptual similarity knowledge; it is based solely on a general mathematical learning method that achieves powerful inductive effects by extracting the right number of dimensions (e.g., 300) to represent objects and contexts. Relations to other theories, phenomena, and problems are sketched.” (Landauer & Dumais, 1997). Therefore, the article by Landauer and Dumais has an important contribution to make toward this comparative analysis of semantic analysis methods and the paper makes use of the literature in the article.
Latent Dirichlet Allocation (LDA) is a generative probabilistic model for collecting discrete data such as text corpora and David M Blei et al deals with this model very exclusively in their article “Latent Dirichlet Allocation”. According to them, Latent Dirichlet Allocation is “a three-level hierarchical Bayesian model, in which each item of a collection is modeled as a finite mixture over an underlying set of topics. Each topic is, in turn, modeled as an infinite mixture over an underlying set of topic probabilities. In the context of text modeling, the topic probabilities provide an explicit representation of a document.” (Blei, Ng & Jordan, 2003, p. 993-1022).
In their paper, they have been able to present efficient approximate inference techniques based on variation methods and an EM algorithm for empirical Bayes parameter estimation. The value of the paper by David M Blei et al is that it deals with document modeling, text classification, and collaborative filtering in detail and makes a comparative analysis with different unigrams model and the probabilistic LSI model.
Therefore, it is important to clarify that the paper reflects on the problem of modeling text corpora and other collections of discrete data with a purpose “to find short descriptions of the members of a collection that enable efficient processing of large collections while preserving the essential statistical relationships that are useful for basic tasks such as classification, novelty detection, summarization, and similarity and relevance judgments.” (Blei, Ng & Jordan, 2003, p. 993-1022). The validity of the article by David M Blei et al is, therefore, unequivocal and this comparative study of the semantic analysis methods reviews the article very scrupulously.
Another most relevant article in this analysis is “Probabilistic latent semantic analysis” by Thomas Hofmann in which a profound analysis of the Probabilistic Latent Semantic Analysis has been carried out. According to the article, Probabilistic Latent Semantic Analysis (pLSA) is “a novel statistical technique for the analysis of two-mode and co-occurrence data, which has applications in information retrieval and filtering, natural language processing, machine learning from text, and in related areas.” (Hofmann, 1999).
In the article, Hofmann proposes the new method of semantic analysis which is based on a combination decomposition derived from a latent class model. In comparison with the standard Latent Semantic Analysis which is the result of linear algebra and executes a Singular Value Decomposition of co-occurrence tables, the pLSA enjoys greater advantage as it is more principled approach with a solid foundation in statistics.
The approach as suggested by Hofmann yields substantial and consistent improvements over Latent Semantic Analysis in a number of experiments and this also has significance in the given background. (Hofmann, 1999). The validity of the article in the comparative analysis of semantic analysis methods is immense, mainly because it gives a complete picture of Probabilistic Latent Semantic Analysis.
In another of the most essential articles on semantic analysis, “Term Weighting Approaches in Automatic Text Retrieval” by Salton and Buckley concentrates on the approaches of term weighting and makes pertinent conclusions regarding the most effective approach. There have been significant experimental evidences collected over the past 20 years or so, which suggest that text indexing systems using the assignment of properly weighted single terms generate recovery results that have greater advantage compared to those accessible with other more complicated text representations.
These retrieval results depend primarily on the choice of effective term weighting systems. It is important that the article by Salton and Buckley “summarizes the insights gained in automatic term weighting, and provides baseline single-term-indexing models with which other more elaborate content analysis procedures can be compared.” (Salton & Buckley, 1987). In this regard, the utility of this scientific article in a comparative analysis of the different semantic analysis methods is immense. It is also based on the review of this article that the comparative study of the different semantic analysis methods is carried out.
In the natural language processing, computational models of text structure has a central role and their growth and application have always been a fundamental concern in this. The contribution of document-level analysis of text structure has been considered a vital example in such works. The researches and studies of the past concentrated mainly on typifying texts in terms of domain-independent rhetorical elements including the schema items and rhetorical relations.
However, the focus has shifted considerably in the works of Regina Barzilay and Lillian Lee. Their work, in comparison with the existing researches, focuses on uniformly fundamental but domain dependent dimension of the structure of text which is called content. The use of the term ‘content’ has great value as it matches up with the ideas of topic and topic change. In their article “Catching the Drift: Probabilistic Content Models, with Applications to Generation and Summarization” Barzilay and Lee “consider the problem of modeling the content structure of texts within a specific domain, in terms of the topics the texts address and the order in which these topics appear.
[They] first present an effective knowledge-lean method for learning content models from un-annotated documents, utilizing a novel adaptation of algorithms for Hidden Markov Models.” (Barzilay & Lee, 2004, p. 113-120). Then they focus on applying their method to the two complementary tasks of information ordering and extractive summarization. Based on their experiments, they argue that incorporating content models in information ordering and extractive summarization yields considerable advancement compared to the earlier methods and thereby conclude on the superiority of their model. Therefore, the article by Barzilay and Lee has an important value in this comparative analysis of semantic analysis methods.
Comparison of the Semantic Analysis Methods Based on Literature Review
The semantic analysis methods have developed through the historical sequences and every model incorporates a set of well defined characteristics and advantages. At some point of their development, the limitations of a specific method provided reasons to formulate an innovative method which modifies the inadequacies of the previous method. It is most essential to maintain that every such methods for semantic analysis contains some common characteristic features which make all these models relevant in the area of semantic analysis. Most significantly, all these semantic analysis models are empirically based rather than motivated by annotation or human intervention and they are constructed on a text corpus.
The various semantic analysis models such as latent semantic analysis (LSA), probabilistic latent semantic analysis (pLSA), latent dirichlet allocation (LDA), probabilistic content models and term frequency–inverse document frequency (tf-idf) share some common features. One of the remarkable features among them is that they are applied to longer length passages from paragraph length consisting of several sentences to document length which may contain multiple paragraphs. In this paper, a comparison of these models along with their strengths, weaknesses and their intended application will be stressed.
In this comparative analysis of the most pertinent semantic methods, one of the foremost methods has been the latent semantic analysis (LSA). It is primary to comprehend that the latent semantic analysis is a high-dimensional linear associative model which, represents no human knowledge beyond its general learning mechanism, to analyze a large corpus of natural text and generate a representation that captures the similarity of words and text passages.
Several attempts to test the model’s resulting knowledge have been made and the standard multiple-choice synonym test helped in the testing. The results of the testing, as Landauer and Dumais indicate, have relevant interpretations. “The more conservative interpretation is that it shows that with the right analysis a substantial portion of the information needed to answer common vocabulary test questions can be inferred from the contextual statistics of usage alone.
This is not a trivial conclusion. As we alluded to earlier and elaborate later, much theory in philosophy, linguistics, artificial intelligence research, and psychology has supposed that acquiring human knowledge, especially knowledge of language, requires more specialized primitive structures and processes, ones that presume the prior existence of special foundational knowledge rather than just a general purpose analytic device.” (Landauer & Dumais, 1997).
Significantly, this interpretation has doubts regarding the scope and stipulation of such assumptions whereas the more radical interpretation of the result considers the model’s device critically as a possible theory about all human knowledge acquisition. The focus of this discussion is, however, the latent semantic model, aiming at the discussion of the model’s features, strengths and weaknesses. At the outset, it is important to specify that the latent semantic analysis model is an entirely mathematical analysis technique, though it has a broader and more psychological level.
The latent semantic model deems that the psychological similarity between any two words can be clearly seen in the occurrence of these together in the subordinate aspects of the language. The source of language samples can be understood as arranging words in a way that there is arranged stochastic mapping between semantic similarity and output distance. Such an arrangement suits the pair-wise similarities into a common space of high dimensionality.
It is important to comprehend the psychological description of LSA as a theory of learning, memory, and knowledge. Landauer and Dumais maintain that “the input to LSA is a matrix consisting of rows representing unitary event types by columns representing contexts in which instances of the event types appear… After an initial transformation of the cell entries, this matrix is analyzed by a statistical technique called singular value decomposition (SVD) closely akin to factor analysis, which allows event types and individual contexts to be re-represented as points or vectors in a high dimensional abstract space. The final output is a representation from which one can calculate similarity measures between all pairs consisting of either event types or contexts.” (Landauer & Dumais, 1997). The data acquired as raw data goes through a process of development which may be interpreted psychological.
The transformation of every cell entry in the initial data from the number of times that a word appeared in a particular context to the log of that frequency may be regarded as the primary step of the LSA analysis. Then every cell entry will be divided by the entropy for that word, -Z p log p over all its contexts, which forms the second transformation. At a final stage the LSA makes use of a computational scheme in order to combine and condense local information into a universal representation captures multivariate correlation contingencies among all the events about which it has local knowledge.
However, the method mainly focuses on a mathematical process through which the semantic analysis can be represented statistically. The LSA method, through a mathematically distinct and well-defined sense, enhances the effectiveness of prediction of the presence of all other events from those currently identified in a given context. Therefore, the mathematical explanation of the LSA method can offer a clear picture of the features and working of the method.
Offering an explanation of the process of the method using the terminology of neural net models, Landauer and Dumais in their study make some pertinent points. This explanation of the method using the neural net models is especially significant in an understanding of the strengths and weaknesses of the semantic analysis method.
They make use of the conceptual explanation of the LSA model and compare it to a simple but rather large three-layered neural net. “It has a Layer 1 node for every word type (event type), a Layer 3 node for every text window (context or episode) ever encountered, several hundred Layer 2 nodes–the choice of number is presumed to be important–and complete connectivity between Layers 1 and 2 and between Layers 2 and 3. (Obviously, one could substitute other identifications of the elements and episodes).” (Landauer & Dumais, 1997).
This network is presented as symmetrical which can turn in either direction. The neutral net models have great importance as the network can generate artificial or ‘imaginary’ episodes. These episodes can create ‘utterances’ through the inverse operations in order to symbolize themselves as samples of event types. These advantages are present in the equivalent singular value-decomposition matrix model of LSA as well.
Singular value decomposition (SVD) can be very well comprehended as the most common method for linear decomposition of a matrix into independent principal components. In this method factor analysis is specifically formulated in square matrices and it uses the same entities as columns and rows.
A prudent depiction of all the inter-correlations between a set of variables in terms of a new set of abstract variables are included in the factor analysis finds. The method uses the similar technique for an arbitrarily shaped rectangular matrix in which the columns and rows designate different elements. “The principal virtues of SVD… are that it embodies the kind of inductive mechanism…, that it provides a convenient way to vary dimensionality, and that it can fairly easily be applied to data of the amount and kind that a human learner encounters over many years of experience.” (Landauer & Dumais, 1997).
The evaluation of the LSA model, as attempted by Landauer and Dumais, has been planned most effectively and the process included four pertinent questions which are presented below.
- Can this simple linear model obtain knowledge of humanlike word meaning similarities to a significant extent if a large amount of natural text is given?
- Would its success depend sturdily on the dimensionality of its representation, if at all the first question gives the answer ‘yes’?
- How will its rate of acquirement judge against that of a human reading the same amount of text?
- How much of its knowledge would originate from indirect inferences that unite information across samples rather than straight from the local contextual contiguity information which is included in the input data?
In their analysis of the method, Landauer and Dumais manipulated the data they collected and came up with remarkable conclusions. Thus conclusions on LSA’s acquisition of word knowledge from text, the effect of dimensionality, and the learning rate of LSA versus humans and its reliance on induction etc have been made. The major conclusions from the vocabulary simulations were three in number which are listed in descending order of certainty.
- LSA learns a great deal about word meaning similarities from text, an amount that equals what is measured by multiple choice tests taken by moderately competent English readers.
- About three quarters of LSA’s word knowledge is the result of indirect induction, the effect of exposure to text not containing words used in the tests.
- Putting all considerations together, it appears safe to conclude that there is enough information present in the language to which human learners are exposed to allow them to acquire the knowledge they exhibit on multiple-choice vocabulary tests. (Landauer & Dumais, 1997).
In their study, Landauer and Dumais also make some important findings by generalizing the domain of LSA and they suggest that it is not possible for the mind to utilize the dimensionality optimization just to induce similarities involving words. It is also significant that other aspects of cognition can take advantage from a means to extract more knowledge from a multitude of local co-occurrence data.
The usage and reference of are the most essential aspects of lexical knowledge and the similarity relations on the basis of meaning are the result of the LSA. There are such different aspects in the lexical knowledge which are aided by the use of LSA. It is also most significant to relate at this point that “the LSA model suggests new ways of understanding many familiar properties of language other than word similarity… Indeed, LSA provides a potential technique for measuring the drift in an individual or group’s understanding of words as a function of language exposure or interactive history.” (Landauer & Dumais,1997).
In the current employment of LSA, though taciturn on the temporal dynamics of comprehension, offers an objective way to signify, replicate, and evaluate the degree of semantic similarity between words and between words and longer passages. Therefore, the utility of LSA is beyond doubt.
The effectiveness of the LSA has been set in the background of the problem of induction in knowledge acquisition and a new basis for long-range induction was proposed by the article “A Solution to Plato’s Problem: The Latent Semantic Analysis Theory of Acquisition, Induction and Representation of Knowledge.” This method chiefly depends on reconstruction of a system of multiple similarity relations in a high dimensional space. The study has employed the dimensionality-optimizing induction method as a mathematical matrix-decomposition method. This method is known as singular value decomposition (SVD).
In their investigation, Landauer and Dumais have been able to present the working of SVD through executing the model perceptibly and reproducing word learning. In this attempt, they made use of singular value decomposition in order to assess 4.6 million words which were collected from Grolier’s Academic American Encyclopedia. The arrangement of these data in a matrix of cells, columns and rows has been able to represent the data exactly.
Through their arrangement of the data in the matrix, they were able to represent the working of SVD. The authors provide a schematic illustration of dimension reduction by singular value decomposition (SVD) in the following figure.
The first figure (A) word types are represented as rows, text contexts which contain the words as columns, and transformed raw frequencies as cell entries (x). It is also notable that, in the next two figures (B and C), columns represent the artificial orthogonal factors pulled out from the data, where as the entries of the cells (y and z) originate out of the linear combination of all the data in the upper matrix in a way that is optimal for reconstructing the pattern similarities between words in a smaller number of dimensions. (Landauer & Dumais,1997).
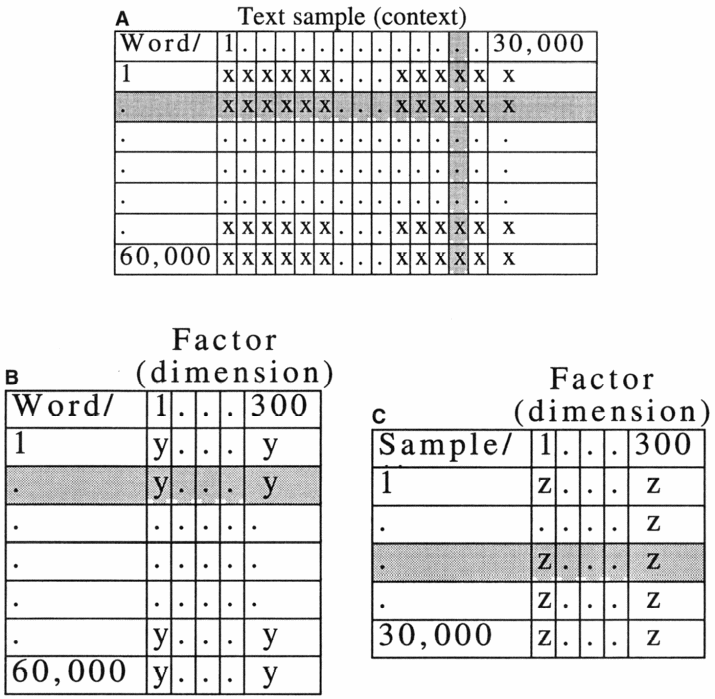
The conclusion they arrived at suggests that optimal dimensionality reduction is the main source of the model’s strength. To explain the working of SVD more specifically, it is notable that the condensed vector for a word is calculated as a linear grouping of data from the different cells in the matrix in the method of SVD.
Here, every type of arrangement and relation including linear relations are used by SVD to determine the values of the condensed vector. The authors, through their original researches, come to the conclusion that SVD opens a new depiction which shares the indirect inferential information when its dimensionality is condensed. Thus, the working of SVD is clearly demonstrated by Landauer and Dumais in their article. (Landauer & Dumais,1997).
Making a concise note on neurocognitive and psychological plausibility, the authors maintain that “the mind-brain stores and reprocesses its input in some manner that has approximately the same effect.” (Landauer & Dumais,1997). It may not mean that the mind or brain absolutely computes a SVD. It has not been specified, in LSA, how the brain constructs an SVD-like result. However, certain arguments regarding the correspondences of SVD have been available.
Landauer and Dumais specify that “Interneuronal communication processes are effectively vector multiplication processes between axons, dendrites, and cell bodies; the excitation of one neuron by another is proportional to the dot product (the numerator of a cosine) of the output of one and the sensitivities of the other across the synaptic connections that they share. Single-cell recordings from motor-control neurons show that their combined population effects in immediate, delayed, and mentally rotated movement control are well described as vector averages (cosine weighted sums) of their individual representations of direction, just as LSA’s context vectors are vector averages of their component word vectors.” (Landauer & Dumais,1997).
They also make it clear that the neural net models may be rearranged as matrix algebraic operations. The employment of vector representations and linear combination operations in various mathematical models of laboratory learning and other psychological processes has brought about the most effective results. Similarly, the vector algebra has been useful in representing some of the semantic network represented theories.
The authors make the conclusion that “LSA differs from prior application of vector models in psychology primarily in that it derives element values empirically from effects of experience rather than either pre-specifying them by human judgment or experimenter hypothesis or fitting them as free parameters to predict behavior, that it operates over large bodies of experience and knowledge…” (Landauer & Dumais,1997).
The investigation has been effectively managed through the testing of the method by simulating the acquisition of vocabulary knowledge from a large body of text. The assessment of the model’s knowledge through a standardized synonym test also suggests the superior quality of the study. The simulation of the acquisition of vocabulary knowledge by school-children in order to measure the performance of the model as well as the induction method also indicates the value of the investigative study.
In the well-managed assessment of the LSA model Landauer and Dumais arrive at the conclusion that the induction method is adequately strong to explain the deficiency of local experience as proposed by Plato. They also have been successful in illustrating the LSA representation of digits can explain why people apparently respond to the log of digit values when making inequality judgments. Another significant factor in this analysis has been that the study proposed a basic associative learning theory of psychological sort which embodies the mathematical model, apart from providing a sample of conjectures as to how the theory would generate novel accounts for aspects of interesting psychological problems, in particular for language phenomena, expertise, and text comprehension.
The article reanalyzed the human text processing data which suggest “how the word and passage representations of meaning derived by LSA can be used to predict such phenomena as textual coherence and comprehensibility and to simulate the contextual disambiguation of homographs and generation of the inferred central meaning of a paragraph. Finally, [it] showed how the LSA representation of digits can explain why people apparently respond to the log of digit values when making inequality judgments.” (Landauer & Dumais, 1997). In short, the scientific study of the Latent Semantic Analysis as undertaken by Landauer and Dumais has been able to contribute some most relevant knowledge and experimental conclusions about the method.
The problem of modeling text corpora and other collections of discrete data has been carefully analyzed by David M Blei et al in their article “Latent Dirichlet Allocation”. They aim at finding short descriptions of the members of a collection which facilitate the able processing of large collections at the same time as conserving the crucial statistical relationships which will be valuable in basic tasks including classification, novelty detection, summarization, and similarity and relevance judgments.
The contributions of the searchers in the field of information retrieval (IR) are remarkable which also helped in the advancements in the problem of modeling text corpora and other collections of discrete data. The researchers of information retrieval put forward a methodology for text corpora which has been found effective in the modern Internet search engines. The important advantage of the basic methodology as used by the IR researchers is that it condenses documents in the corpus to a vector of real numbers and these vectors represent ratios of counts.
“In the popular tf-idf scheme,” David M Blei et al point out, “a basic vocabulary of ‘words’ or ‘terms’ is chosen, and, for each document in the corpus, a count is formed of the number of occurrences of each word. After suitable normalization, this term frequency count is compared to an inverse document frequency count, which measures the number of occurrences of a word in the entire corpus (generally on a log scale, and again suitably normalized).
The end result is a term-by-document matrix X whose columns contain the tf-idf values for each of the documents in the corpus.” (Blei, Ng & Jordan, 2003, p. 993-1022). In this manner, the tf-idf scheme has been useful in trimming down documents of illogical length to fixed-length lists of numbers.
In this comparative analysis of semantic analysis methods, it is of paramount relevance to have a thorough understanding of the tf-idf reduction approach and latent semantic indexing (LSI). It has been well maintained that that the tf-idf reduction incorporates some pertinent characteristics which mainly include its fundamental recognition of sets of words which are discriminative for documents in the collection. However, the approach offers only a moderately minute quantity of decrease in the description length and discloses only little in the way of inter- or intra document statistical structure.
It is in this background, that the significance of latent semantic indexing (LSI) may be comprehended. Latent semantic indexing is the most important dimensionality reduction technique which covers the deficiencies of the existing methods. In the words of David M Blei et al, “LSI uses a singular value decomposition of the X matrix to identify a linear subspace in the space of tf-idf features that captures most of the variance in the collection. This approach can achieve significant compression in large collections. Furthermore… the derived features of LSI, which are linear combinations of the original tf-idf features, can capture some aspects of basic linguistic notions such as synonymy and polysemy.
To substantiate the claims regarding LSI, and to study its relative strengths and weaknesses, it is useful to develop a generative probabilistic model of text corpora and to study the ability of LSI to recover aspects of the generative model from data.” (Blei, Ng & Jordan, 2003, p. 993-1022). However, the applicability and advantages of LSI compared to other models were not specified in the previous studies and it was indistinct the benefits of adopting the LSI methodology. That is to say, the significance of latent semantic index in comparison with the existing methods was not specified.
In this background, the contribution of Hofmann is particularly mentionable and it was he who presented an alternative to LSI in the form of the probabilistic Latent Semantic Index (pLSI) model, otherwise known as the aspect model. It was a significant step in the semantic analysis methods and the probabilistic Latent Semantic Index approach “models the word in the document as a sample from a mixture model, where the mixture components are multinomial random variables that can be viewed as representations of ‘topics.’ Thus each word is generated from a single topic, and different words in a document may be generated from different topics.
Each document is represented as a list of mixing proportions for these mixture components and thereby reduced to a probability distribution on a fixed set of topics. This distribution is the ‘reduced description’ associated with the document.” (Blei, Ng & Jordan, 2003, p. 993-1022).
Thus, Hofmann’s probabilistic Latent Semantic Index model has important advantages compared to the earlier models and his works have functional significance in the development of probabilistic modeling of text. However, the pLSI has been found wanting as it does not provide the probabilistic model at the level of documents. Rather, the documents are represented as a list of numbers which do not have any generative probabilistic model. These deficiencies lead to a number of problems which include,
- the number of parameters in the model grows linearly with the size of the corpus, which leads to serious problems with over-fitting, and
- it is not clear how to assign probability to a document outside of the training set. (Blei, Ng & Jordan).
In the given background of the various limitations of probabilistic Latent Semantic Index model, the developments beyond pLSI may be realized with the help of fundamental probabilistic assumptions which underlie the class of dimensionality reduction methods including LSI and pLSI. In this historical development of the semantic analysis methods, the latent Dirichlet allocation (LDA) model has become a crucial progress.
In the modern world of Artificial Intelligence and Machine Learning, the learning from text and natural language presents an important problem. The developments and advancement in this area would positively affect the various applications including information retrieval, information filtering, intelligent interfaces, speech recognition, natural language processing, and machine translation. Therefore, the modern tendencies bring about several issues that need to be looked into as an immediate next step. Finding out the meaning and usage of words in a data-driven manner presents a crucial issue.
The most important challenges in a machine learning system present some essential problems which may be mainly twofold and they are polysems and synonyms and semantically related words. These central questions may be effectively dealt with in a Latent semantic analysis (LSA) and its “key idea is to map high-dimensional count vectors, such as the ones arising in vector space representations of text documents, to a lower dimensional representation in a so-called latent semantic space.
As the name suggests, the goal of LSA is to find a data mapping which provides information well beyond the lexical level and reveals semantical relations between the entities of interest. Due to its generality, LSA has proven to be a valuable analysis tool with a wide range of applications.” (Hofmann, 1999). However, as Hofmann suggests, LSA lacks a satisfactory theoretical foundation, the statistical view of which leads him to the Probabilistic Latent Semantics Analysis (PLSA) which has a sound statistical foundation.
At this point, it is of paramount relevance to have a comparison between Latent Semantic Analysis and Probabilistic Latent Semantic Analysis. It is often specified that Latent Semantic Analysis has a wider applicability which allows the method appropriate to different types of count data over a discrete dyadic domain. It may be noted that the most fundamental use of LSA is regarding the analysis and retrieval of text documents.
A most important idea of Latent Semantic Analysis has been the mapping of documents to the latent semantic space which is a vector space of reduced dimensionality. This mapping is a linear arrangement and is founded on a Singular Value Decomposition (SVD) of the co-occurrence table. Probabilistic Latent Semantic Analysis has been an important innovative method which sought to deal with the major limitations of the original LSA.
The aspect model of Probabilistic LSA, which is an important statistical model, will be useful in an understanding of pLSA. Another significant element of the Probabilistic LSA is that it is the model which fits the most with the EM Algorithm. According to Hofmann, “The standard procedure for maximum likelihood estimation in latent variable models is the Expectation Maximization (EM) algorithm. EM alternates two coupled steps:
- an expectation (E) step where posterior probabilities are computed for the latent variables,
- a maximization (M) step, where parameters are updated.” (Hofmann, 1999).
There are various such advantages related with the method of Probabilistic Latent Semantic Analysis which make it a superior alternative to the original LSA method. Through the investigative research, it has been well maintained that Probabilistic Latent Semantic Analysis, the novel method for unsupervised learning is one of the most effective methods of semantic analysis. This approach, which is based on a statistical latent class model, has a superior viability and it is more principled than standard Latent Semantic Analysis because it acquires a sound statistical foundation. In his study Hofmann makes it clear that Tempered Expectation Maximization is one of the most powerful fitting procedures.
The investigation undertook experiments in verifying the claimed advantages achieving substantial performance gains and it has been concluded that “Probabilistic Latent Semantic Analysis has…to be considered as a promising novel unsupervised learning method with a wide range of applications in text learning and information retrieval.” (Hofmann, 1999).
“Catching the Drift: Probabilistic Content Models, with Applications to Generation and Summarization” by Barzilay and Lee has been an important article in a deep understanding of the probabilistic content model. Significantly, the paper examines the utility of domestic specific content models for representing topics and topic shifts. In this efficient knowledge lean method learning, both set of topics are described first.
Then their relations with other topics directly from un-annotated documents are presented. This is a very novel technique which has been considered high for its advantage. It is an incorporation of HMM (Hidden Markov Models) and is based on content model. It has an advantage over the two- complex text processing task. Information regarding ordering is the first task i.e. selection of sequence to present in pre-selected items. Extractive summarization is the next task. A content model-based-learning algorithm is developed for sentence selection. It has achieved a very impressive success rate. Though it shows flexibility and effectiveness, its practicability is yet to ascertain.
In the article, the authors describe a competent, knowledge-lean method for learning both a set of topics and the relations between topics directly from un-annotated documents. The knowledge-rich method is applicable even to people who do not have any domain-based knowledge. In the knowledge-lean approaches provide for the immediate development of the model construction. Topics are considered as a useful auxiliary variable rather than a central concern. Contents are treated as a primary entity. The object of the application of algorithms is to modeling document content. This differentiates it from the standard Bawb-Welch or (EM) algorithm application for modeling content.
In model construction, an interactive re-estimation procedure is employed. Texts are treated as sequences of pre- defined text spans. Sentences are referred rather than text spans. Text spans are used here for experiments only. It is pointed out that paragraphs or clauses can also be used instead. It is assumed that all texts from a given domain are generated by a single content model. This method has a substantial improvement over the other existing methods.
This paper clearly illustrates with examples the difference between domain specific application and generic principle. Text level applications can be made by applying distributional approaches. Hidden Markov Models can also be used for the application to create content structure. It is relatable here that the paper is very successful in presenting many facts to show the advantages of the Probabilities Content Model over the existing ones.
In the paper by Barzilay and Lee, an unsupervised method for the induction of content models has been proposed and this incarcerates constraints on topic selection and organization for texts in a particular domain. According to them, these models have immense validity in the ordering and summarization applications as they possess considerable perfection in comparison to the early methods. As they conclude, the results of the study “indicate that distributional approaches widely used to model various inter-sentential phenomena can be successfully applied to capture text-level relations, empirically validating the long-standing hypothesis that word distribution patterns strongly correlate with discourse patterns within a text, at least within specific domains.” (Barzilay & Lee, 2004, p. 113-120).
Accordingly, the future studies may concentrate on the association between the domain-specific model presented in the paper and domain-independent formalisms. The most important application of the study by Barzilay and Lee is that it reveals appealing connections that exist between domain-specific stylistic constraints and generic principles of text organization. The application of probabilistic context-free grammars or hierarchical Hidden Markov Models in the modeling content structure also is specified in the study.
The enhancement of retrieval effectiveness is the foremost purpose of a term-weighting system and the effective retrieval mainly depends on two factors. First, the items that are expected to be significant to the user’s needs must be retrieved. Second, the items which are likely to be superfluous must be rejected. Recall and precision are two of the measures that are commonly used in assessing the ability of a system to retrieve the relevant and reject the irrelevant. The proportion of relevant items retrieved, measured by the ratio of the number of relevant retrieved items to the total number of relevant items in the collection is called recall.
On the other hand, precision may be understood as the proportion of retrieved items that are relevant which is measured by the ratio of the number of relevant retrieved items to the total number of retrieved items. The system that ensures high recall by retrieving relevant items as well as high precision by rejecting extraneous items is considered great. The use of wide and high-frequency terms which arise in various documents of the collection has been found effective in the recall function of retrieval. On the other hand, narrow and extremely specific terms which can cut off the few relevant items from the mass of non-relevant ones seem to be useful in the precision factor.
However, there are various compromises in this regard. The change in recall and precision requirements cause the implementation of complex term weighting factors and this comprises of recall as well as precision enhancing components. In this background, there are three chief considerations which need mention. Salton and Buckley list these factors as follows: “First, terms that are frequently mentioned in individual documents, or document excerpts, appear to be useful as recall enhancing devices… Second, term frequency factors alone cannot ensure acceptable retrieval performance. Specifically, when the high frequency terms are not concentrated in a few particular documents, but instead are prevalent in the whole collection, all documents tend to be retrieved, and this affects the search precision…
A third term-weighting factor, in addition to the term frequency and the inverse document frequency, appears useful in systems with widely varying vector lengths.” (Salton & Buckley, 1987). The first aspect suggests that a term frequency (tf) factor may be used as a component of the term-weighting system which measures the frequency of occurrence of the terms in the document or query texts. Significantly, term-frequency weights have been used for many years in automatic indexing environments.
The second aspect in this list indicates that the search precision can be affected and so a new collection-dependent factor needs to be used which can assist terms concentrated in a few documents of a collection. The inverse document frequency (idf) which is also called inverse collection frequency factor can be useful in this regard. Notably, the idf factor varies inversely with the number of documents n to which a term is assigned in a collection of N documents and the formula to compute a usual idf factor is log N/n.
In this analysis, it is also important to have a good understanding of the various term-weighting experiments which makes of the different combinations of term frequency, collection frequency, and length normalization components. In their investigation, Salton and Buckley came up with the following conclusions. Accordingly, the query vectors are the following.
- Term-frequency component
- For short query vectors, each term is important; enhanced query term weights are thus preferred: first component n.
- Long query vectors require a greater discrimination among query terms based on term occurrence frequencies: first component t.
- The term-frequency factor can be disregarded when all query terms have occurrence frequencies equal to 1.
- Collection-frequency component
- Inverse collection frequency factor f is very similar to the probabilistic term independence factor p: best methods use f.
- Normalization component
- Query normalization does not affect query-document ranking or overall performance; use x. (Salton & Buckley, 1987). In the same way, the document vectors include the following.
- Term-frequency component
- For technical vocabulary and meaningful terms (CRAN, MED collections), use enhanced frequency weights: first component n.
- For more varied vocabulary, distinguish terms by conventional frequency weights: first component t.
- For short document vectors possibly based on controlled vocabulary, use fully weighted terms: first component b = 1.
- Collection-frequency component
- Inverse document-frequency factor f is similar to probabilistic term independence weight p: normally use f.
- For dynamic collections with many changes in the document collection makeup, the f factor requires updating; in that case disregard second component: use x.
- Length-normalization component
- When the deviation in vector lengths is large, as it normally is in text indexing systems, use length normalization factor c.
- For short document vectors of homogeneous length, the normalization factor may be disregarded; in that case use x. (Salton & Buckley, 1987). In the article, they also suggest the most recommendable single-term weighting systems which may be typical for comparison with enhanced text analysis systems using thesauruses and other knowledge tools to produce complex multi-term content identifications. They are: best document weighting tfc, nfc (or tpc, npc); and best query weighting nfx, tfx, bfx (or npx, tpx, bpx).
Conclusion
This paper has focused on a comparative analysis of the various semantic analysis methods through a profound review of the existing literature on the topic. Through this creative survey in which the most accessible works in the area have been summarized and critiqued, a deep understanding of the most significant semantic analysis methods with their strengths and weaknesses has been made. In other words, the emphasis of the paper has been to supply a cavernous and comprehensive insight into premium research that is obtainable on the scientific topic.
An examination of the various unsupervised and data driven semantic models has been conducted and the result of the study has been pertinent as it suggests some pertinent factors regarding different semantic analysis methods. The use of semantic analysis in representing words, sentences, documents and other units has been often stressed in the current times. The models latent semantic analysis (LSA), probabilistic latent semantic analysis (pLSA), latent dirichlet allocation (LDA), probabilistic content models and term frequency–inverse document frequency (tf-idf) suggest some important common features among them.
Thus, it is concluded that these models are empirically based rather than motivated by annotation or human intervention and are constructed on a text corpus. Additionally, they are also applied to longer length passages from paragraph length comprising several sentences to document length which may comprise of multiple paragraphs. The study also makes pertinent conclusions on the significant strengths, weaknesses and intended application of the various methods of semantic analysis.
References
Barzilay, R., & Lee, Lillian. (2004). Catching the drift: Probabilistic content models, with applications to generation and summarization. HLT-NAACL: Proceedings of the Main Conference, p. 113-120.
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3, 993-1022.
Hofmann, T. (1999). Probabilistic latent semantic analysis. In Proceedings of the 15th Conference on Uncertainty in AI.
Landauer, T. K., & Dumais, S. T. (1997). A solution to plato’s problem: The latent semantic analysis theory of acquisition, induction and representation of knowledge. Psychological Review, 104(2), 211-240.
Salton, G., & Buckley, C. (1987). Term weighting approaches in automatic text retrieval. Technical Report. UMI Order Number: TR87-881, Cornell University.