Abstract
Disaster recovery planning – DRP and business continuity plan – BCP have become very crucial in the current scenario with increased threats from natural and man-made disasters. These disasters effectively wipe out the intellectual and soft assets of a company; taking it a few years back, if the entire source code and transaction records are lost. DRP implementation helps an organisation to quickly restore its networks and retrieve the software applications, account details and transaction records of the customer so that losses are minimised and the company can resume normal operations in the quickest possible time.
The thesis has researched a framework for implementation of DRP and BCP among the 12 Companies. Given in the document are implementation details for various scenarios such as earthquakes, hurricanes, hacking and other threats. In addition to presenting implementations of networks and architecture, it has also presented the steps to be followed for DRP and BCP implementation. The thesis has also presented results of a research in which a survey instrument was used to gather the responses of experts in IT industries. The survey instrument helps in studying three key areas of DRP- cost of downtime, perceived importance of DRP and current state of DRP within organisation with respect to the DRP process. The instrument had three sets of questions that asked for responses for different aspects of the DRP.
The findings are that DRP systems are designed to protect at least 95% of the assets and that organisations have a positive attitude in providing budgets for DRP. All the surveyed organisations use their in house training programs, keep their systems updated, test and maintain them at regular intervals. The report is expected to help organisations and students who want to implement DRP or research this area for further study.
Introduction
Organisations across the globe operate under conditions that are subject to change, depending on the political situation, economic, and natural conditions. Along with increased opportunities, globalisation also brought in increased vulnerability to threats and multi national companies are especially vulnerable to such severe disruptions in service if even one of their units is taken out due to a disaster. Businesses are constantly under the threat of disasters, such as earthquakes, terrorist attacks, fire, riots, power outages, and stock market crash. Due to such risks, the intellectual assets, such as classified documents, source codes, and physical assets, such as infrastructure and hardware, run the risk of compromise.
In such a situation, a plan must be in place to allow business to recover their intellectual and physical assets and continue the business operations, at the earliest. Such plans are called Disaster Recovery Plan – DRP and Business Continuity plan. These plans assure clients and business partners, who have invested time and resources in an organisation, that in case of a disaster, their investments could be recovered in an acceptable time frame.
To handle such situations, it is important to have an IT disaster recovery plan that is implemented to counter the effects of disasters. Having a DRP and BCP becomes important, when business expands to overseas market. While DRP and BCP will not prevent disasters from happening or prevent the loss of lives and property, they would certainly help to reduce the loss caused by delay in restarting the operations and mainly they would help in recovering very valuable company data and information. This thesis discusses the important elements of a DRP and BCP for a company with global operations.
Problem Definition
Recent events such as the 9/11 attacks, Katrina hurricane, the Tsunami in south east Asia and others show that disaster, both natural and man made can strike with very little warning and totally take out the infrastructure that has been built such as buildings, whole towns and cities, cabling and any IT systems that are located in a particular location. Benton (2007) defined disaster recovery as “the process, policies and procedures of restoring operations critical to the resumption of business, including regaining access to data (records, hardware, software, etc.), communications (incoming, outgoing, toll-free, fax, etc.), workspace, and other business processes after a natural or human-induced disaster”. While a disaster recovery would also involve reconstruction of buildings, relocating people, building roads, restoring power and communications and many other activities, this paper would be limited to discussing the disaster recovery plan for the IT systems of a company (Meade, 1993).
In the current environment, the threat from terrorists and from nature places IT systems at a high risk. Since many companies have very strict rules regarding retrieval and storage of sensitive information, data tends to get centralized. If a disaster strikes the central server room where the data is stored, then all the company’s soft assets would be lost forever. Information about customers, business strategies and records, marketing and trading information and other details would become irrecoverable. In such a scenario, strategic plan that protects all computer-based operations necessary for the company’s day-to-day survival is imperative.
If a company loses sensitive data, then it not only loses its soft asset but also the confidence of the customers and would probably go bankrupt. With increasing use of IT systems and dependence on business-critical information, the importance of protecting irreplaceable data has become a top business need. Since many companies rely on IT systems and regard it as critical infrastructure the need for regular backup is very crucial that even after a disaster strikes, the company can begin operating within a short period of time.
Many large companies provide up to 4 percent in their IT budget on disaster recovery systems. It is estimated that 43 percent of companies that had lost data and could not replace the data went bankrupt while 51 percent had to shut down in two years while only six percent could service in the long run (Swartz, 2004).
So DRP and BCP are required to ensure that a company is able to recover quickly in case of a disaster, customer confidence is retained and that the business is able to continue.
Aims and Objectives of the Study
The present study aims to present a framework for effective DRP and BCP by combining different risks, identifying and management strategies into single integrated strategy with which organisations can effectively respond to changes in the form of opportunities, risks and regulations. DRP and BCP practices some top international companies have been researched and views of experts in these companies have been presented.
Research Questions
The following research questions are proposed:
- Assess the framework requirement for implementing DRP and BCP activities in organisations that may have only one or more development centre
- Ascertain the architecture used by different companies that have successfully implemented DRP and BCP plans
- Assess the extent of importance given to DRP and BCP in different companies, their impact exposure to risks, budget and types of applications that are covered in the DRP and BCP plans
Rationale of Research
DRP plan is intended to provide a framework within which companies can take decisions promptly during a business disruption. The objectives of this plan are (Kaye, 2006):
- To identify major business risks.
- To proactively minimize the risks to an acceptable level by taking appropriate preventive and/or alternative measures.
- To effectively manage the consequences of business interruption caused by any event though contingency plans.
- To effectively manage the process of returning to normal operations in a planned and efficient manner.
The scope of the corporate business continuity management plan document must include plans for restoring:
- SBUs (Strategic Business Units) and all the Projects being executed by the SBUs
- Shared services
- Information Systems at all locations of the company
Need and Significance of the Study
The purpose of this study is to develop an effective DRP framework and BCP for IT organisations that provide products and services. Today’s business environment is characterized by brisk and unpredictable change. Some of those changes bring opportunities for business, while others bring challenges and threats to organisation. Irrespective of it, business has to be responsive and resilient by making good use of opportunities while mitigating risks.
Organisational infrastructure must be designed and planned for the continuity of business in case of any disasters. The contemporary definition of disaster concludes that it is a situation created by major events rather than event itself, and specifically the socio economic development and political consequences of event, which forms the key defining aspect of disaster. However, there are number of definitions for ‘disaster’ which focuses on actual hazard or event and its effect in terms of loss of life and damage to property.
In 1961, Fritz, for an instance, defined disasters as “events that are concentrated in time and space, in which a society, or a relatively self-sufficient subdivision of a society, undergoes severe danger and incurs such losses to its members and physical appurtenances that the social structure is disrupted and the fulfilment of all or some of the essential functions of the society is prevented” (Fritz 1961, p. 202). In 1992, the United Nations recognised that for an event to be disaster, it must overwhelm the response capability of a community (Coppola, 2007).
Disaster recovery planning is a recurring process, which has the goal of maintaining the availability of information or service, even in the event of a disaster. In the words Roar Toresen the IT-Manager at Storebrand ASA, “disaster occurs when one has an inability to perform his critical business functions within an acceptable period and it introduces two important issues: one, what is critical, and two, what is an acceptable period”. This varies from company to company. Fluctuating business conditions are like double-edged sword, any inappropriate response could loose ground to their competitors.
For example, if online banking system of TSB Lloyds fails and if it could not restore the operations with in a day, it will loose its majority of customers to its competitor bank. As said by a Bjørn Hovland the IT-Manager at Norske Shell as, “there is a need to balance between the cost of protecting business against every conceivable eventuality and the risk of not protecting at all. The means of achieving this balance is through identifying disasters that are most likely to occur and plan for business continuity in each scenario”. This rises to need for an effective framework for disaster recovery planning which can balance all key issues involved.
Most people when faced with mystifying scope of disaster planning are overwhelmed. The subject is so large with high stakes and the time needed to deal with preparatory issues is so tedious that many firms think that it is easier to do nothing. The importance of disaster recovery planning for organisations are well documented but it is however unclear whether majority of business community is aware of this. As a result, there is limited information on the acceptance of recovery planning outside academic world and even less within the business community.
Companies surveyed for the thesis
A number of companies were approached and IT managers in these companies were asked to complete a survey instrument that posed a set of 20 questions about their IT DRP and BCP. The responses to the queries are presented in Chapter 7 Research Findings and Analysis. The experts have pointed out that the DRP and BCP plans. Details of the companies and IT managers who participated in the survey are given in the following table.
Table 1.1. Company Names and Contact Details.
The above companies have very sizeable investment in IT and use extensive computerisation as a part of their organisation strategy and have branches spread across different countries and continents. About 98% of their work is in the form of computer assets and all documents, work orders, inventory records, purchase order records. Supply chain information, salary and employee records, details of different units and other are stored on computers.
While they have extensive physical infrastructure, communication is through Wide Area Networks or through web enabled systems. Moreover, all the units are integrated and information can be accessed through the computers, on any business functions, subject to users access rights. So for these companies, protection of their IT systems becomes very crucial.
Main Research Findings
An analysis of the survey instrument has revealed the following information:
- The impact of a disaster due to downtimes varies from minor to critical and this indicator depends on the nature of the effected business.
- All the surveyed organisations have some form of DRP in place or in an advanced state of implementation.
- Organisations do not think that cost of protecting business against conceivable eventuality is higher than the risk of not protecting at all.
- With respect to cost of downtime, organisations do not think that the organisation can recover easily after disaster without effective DRP in place.
- The quantitative business impact analysis was done for a number of factors such as ‘Loss of new business; Contractual penalties and regulatory fines; Lost interest on funds; Borrowing expense; Loss of existing business; Additional compensation paid to counter parties; Effect on operational capital – value of funds inaccessible and Extraordinary expenses – resources to address disruptions. As per the responses 37.5 % showed that the impact would be high, 25 % showed that the impact would be medium while 37.5% said that the impact would be low. The impact perception differed for each factor and depended on the type of industry and service offered. Typically, organisations in oil exploration, banking and financial services, retail felt that the impact would be high for some factors.
- The qualitative analysis was done for a number of factors such as Cash Flow, Finance reporting and control, Client services – customer perception, Competitive advantage, Legal or contractual violation, Regulatory requirement, Third party relations, Public image, Industry Image, Employee morale, Work backlog, Professional reputation and Employee turnover. While 15% of the respondents said that the impact would be high, 48% said that the impact would be medium and 15 % said that the impact would be low. So qualitative impacts are substantial in case of disasters.
- Organizations that operate from multiple locations usually have a central team that is charge of the DRP/ BCP plan and are supported by smaller teams at each location.
- Organisations have different priorities for specific application streams that are to be recovered and while the RTO varies between 12 to 24 hours, the RTO varies between 8 to 10 hours.
- Data backup is usually done at day end and in the night when there are very few employees and customers so that network speed does not effect their business.
- Organisations use different types of media such as CD and Tape for data backup and these media are periodically interchanged between locations so that if one location is damaged, tape data from another unit can be used.
- Volume of data back up varies from 1 GB to 10 TB.
- Organisations take up periodic testing of backed up data that may be quarterly or yearly and carry out audits to ensure that data integrity is not compromised.
- In a majority of the surveyed companies, processing capacity of the back-up facility was equal to that of the primary facility.
- Organisations use MPLS VPN – Multi Protocol Label Switching Virtual Private Network for connectivity with back up centres and they use ISDN and other connectivity for non-critical applications and mail services.
- All the companies selected No when asked if they use any specialised off the shelf software and indicated that they have developed their own system for carrying out the DRP/ BCP implementation and invoking. Third party applications have been used for encryption and decryption.
- While larger companies had some kind of DRP/ BCP since the past couple of decades, other companies started the implementation post 9/11 attacks when organisations realised that disasters can happen at any time and from anywhere.
- All the respondents selected Critical as the importance they gave to DRP and BCP.
Expected Outcome of the Study
The study is expected to help companies to assess the state of their DRP and BCP plans and would help them to create feasible plans that would protect them in the case of a disaster.
How this report is organised
The report is structured into various chapters and each chapter provides in depth discussion of different aspects related to the research.
- Chapter 2. Literature Review: The chapter provides a discussion of DRP and BCP, different levels of threats that a company should prepare for. A discussion of what data to back up and risk assessment has also been provided.
- Chapter 3. Research Methodology: The chapter discusses various methodologies such as qualitative and quantitative available and the method adopted for the research. The questionnaire used in the thesis has also been presented.
- Chapter 4. Framework for the DRP plan: The chapter presents frameworks for DRP implementations that have been done in different IT organisations and discusses the various steps involved in DRP implementation. Information about the implementation has been obtained through site visits to IT companies and through emails.
- Chapter 5. Framework for the BCP Plan: The chapter presents frameworks for BCP implementations that have been done in different IT organisations and discusses the various steps involved in DRP implementation. Information about the implementation has been obtained through site visits to IT companies and through emails.
- Chapter 6. Research Analysis and Findings: The chapter discusses results of the survey instruments that have been used to obtain information about the DRP and BCP implementations in various organisations.
- Chapter 7. Conclusions: The chapter draws conclusions and makes recommendations for DRP and BCP implementations.
References: The section provides a list of references used in preparing the report. The range of references used include books, peer reviewed journals, reliable websites and others sources.
Literature Review
This section provides a literature review of important concepts related to risk management and threat levels that have to be considered for the DRP activities.
Understanding the importance of DRP and BCP
When Hurricane Katrina struck the Gulf Coast in August 2005, it damaged 90,000 square miles, an area the size of Oregon. Fully 750,000 people were left homeless in New Orleans alone, and Mississippi’s coastal area had 110,000 more displaced people. The storm caused the largest migration of doctors since World War II and closed insurance offices and financial services companies along with most other businesses in the disaster area.
Communities were inundated by water, causing local government employees to flee. Fifty-four New Orleans Police Department (NOPD) employees were ultimately fired for dereliction of duty for leaving their posts during the storm, and 247 were “AWOL” one week after the storm. Eighty percent of NOPD’s 1 ,700 employees were rendered homeless by the storm, and 700 NOPD members and their families (along with 200 fire department members and their families, sheriff deputies, emergency medical services staff, and essential government workers) lived on a cruise ship rented by the Federal Emergency Management Agency (FEMA) for six months after the storm.
FEMA usually provides trailers as disaster housing, but in New Orleans there was no place to put a trailer that had the necessary water and sewer hook ups available. While the damage to physical infrastructure was large and massive, buildings can be rebuilt. The loss of data, financial records, details of transactions lost, banking accounts and credit information that was lost was irreplaceable and many people who had healthy bank accounts were rendered bankrupt in a few hours of natures fury (Edwards, 2006).
Potter (3 April 2003) reports that after the 9/11 attacks devastated the New York twin towers at the trade centre, in addition to the thousands of people who lost their lives, the buildings hosted many banking and financial institutions. Very valuable information about the records and transactions done, money transfer details, shares and stocks trading information, information on debt instruments and others were lost. The loss happened simply because the companies did not fully implement the DRP activities.
The author reports that though almost all companies back up their critical IT systems and data, more than a quarter of them still do not have a disaster recovery plan in place. Half of those that do have plans, fail to test them. Also, 15% of companies do not take their backups off-site. This is despite the fact that 92% of businesses now consider disaster recovery planning an important driver of their IT expenditure. About 58% of businesses surveyed would suffer significant business disruption if their IT systems were not available for a day – the highest figure recorded since the surveys began. This rises to 70% of large companies.
Some 68% of companies polled believe that business continuity in a disaster situation is a very important driver of their information security expenditure, and a further 24% say it is important. Only 2% say it is not very important. Adding further, the author points that 28% of companies do not have a disaster recovery plan in place, almost half of the disaster recovery plans have not been tested in the last year and 10% of companies with a disaster recovery plan do not store backups off-site. When companies suffered a systems failure or data corruption incident, 31% had no contingency plan in place and a further 10% found their contingency plan to be ineffective.
The year 2000 problem has raised the business continuity consciousness level of business. Where year 2000 risks have been mitigated, contingency plans have been developed just in case. Businesses have been forced to assess their resilience in the face of the threat that the millennium bug will cause their systems to crash. Leveraging this learning, some IT professionals have taken the opportunity to extend contingency plans to cover not just year 2000 issues, but broader disruptions, thereby making the most of the year 2000 problem and seizing a great opportunity.
In the past, disaster recovery was provided for production applications as a matter of practice. Whatever was needed for recovery was provided at the time an application was moved into production status. If these needs were not met, the application did not go into production until they were. It was that simple. And since the mainframe that ran the applications was tightly managed, rules were easy to enforce.
Computers on every desktop and client server computing, all under distributed management. The new generation of manager was under pressure to deliver, and often knew very little about the disciplines of the data centre, specifically production turnover, change management and capacity planning. In fact, these disciplines were often seen as impediments to fast action. As the mission critical applications moved to distributed servers under distributed management, disaster recovery plans were inconsistently developed and tested. At the same time, business continuity planning became essential as technology became indispensable for the conduct of business.
So disaster recovery planning conceptually broadened to encompass business continuity planning. But to this observer, both concepts are, more often than not, dealt with after the fact. We’re inspecting disaster recovery and business continuity into existence rather than engineering them in. And there is not enough managerial support for the work that has to go into the proper approach; the people responsible for these issues are fighting for attention and budget.
The lack of serious attention paid to disaster recovery has, in some cases, been enough to put mission critical applications at severe risk. The most appropriate moment to incorporate recovery and contingency is at the time of development and implementation (Facer, 2001).
Following figure shows the relation between the amount of money spent on DRP and the probability of the systems being affected.
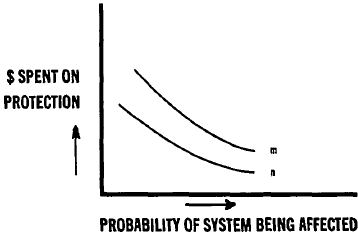
The importance of DRP and protecting IT systems increased as more and more information systems directly interacted with the general public and there are demands for guaranteed continuous operation. IT spending on DRP is in many cases done grudgingly and IT managers are forced to watch the bottom line to ensure that projects do no fall into the red since while expenses are made there are no ‘returns’ on the investment.
But such attitudes are often myopic and it is only after a disaster strikes that managers begin to realise the importance of DRP plans but by then it is too late. Another problem is that after a DRP is implemented, periodic maintenance, updating and testing is not done and one realises that vital links in the plan are missing and an incomplete DRP is as bad as not having a plan at all (Gilchrist, 2001).
Understanding Risk Analysis and Management
Risk and Threat analysis forms a very important aspect of the DRP and BCP plan and an assessment of the risk is very crucial to a business. Risk grows from threats and any unforeseen even can be a threat. There are different types of risks that DRP and BCP do not cover and these include business risks such as failed products, increased competition, change in technology and customer preferences, change in government policies and so on. Risk is associated with the uncertainty of financial loss, the variations between actual and expected results, or the probability that a loss has occurred or will occur.
A risk assessment analysis is a rational and orderly approach, and a comprehensive solution, to problem identification and probability determination. It is also a method for estimating the expected loss from the occurrence of some adverse event. The key word here is estimating, because risk analysis will never be an exact science and we are discussing probabilities. Nevertheless, the answer to most, if not all, questions regarding one’s security exposures can be determined by a detailed risk-assessment analysis.
Risk analysis provides management with information on which to base decisions. Is it always best to prevent the occurrence of a situation? Is it always possible? Is it sufficient simply to recognize that an adverse potential exists and for now do nothing but be aware of the hazard? The eventual goal of risk analysis is to strike an economic balance between the impact of risk on the enterprise and the cost of implementing prevention and protective measures.
- A properly performed risk analysis has many benefits, a few of which are:
- The analysis will show the current security posture (profile) of the organization.
- It will highlight areas where greater (or lesser) security is needed.
- It will help to assemble some of the facts needed for the development and justification of cost effective countermeasures (safeguards).
- It will serve to increase security awareness by assessing then reporting, the strengths and weaknesses of security to all organizational levels from management to operations.
Risk analysis is not a task to be accomplished once and for all; it must be performed periodically if one is to stay abreast of changes in mission, facilities, and equipment. Also, since security measures designed at the inception of a system generally prove to be more effective than those superimposed later, risk analysis should have a place in the design or building phase of every new facility. Unfortunately, this is seldom the case.
The one major resource required for a risk analysis is trained manpower. For these reason the first analysis will be the most expensive. Subsequent analyses can be based in part on previous work history; the time required to do a survey will decrease to some extent as experience and empirical knowledge are gained. The time allowed to accomplish the risk analysis should be compatible with its objectives. Large facilities with complex, multi shift operations and many files of data will require more time than single-shift, limited production locations. If meaningful results are to be expected, management must be willing to commit the resources necessary for accomplishing this undertaking. It is best to delay or even abandon the project unless and until the necessary resources are made available to complete it properly.
Estimating Threat Levels
There are four levels of disasters that an organization would face and the effects of each level and the disaster recovery plan would differ as per the level such as Level 1 to Level 4. Level 1 would be the least severe while Level 4 would be regarded as a catastrophe.
Disasters can be classified into (Preston, 1999):
- Level 1 Disaster: Causes minor outage. An example of Level 1 disaster is modem failure. Some or all business processes at a location might experience minor damage, but processes will continue to run with reduced efficiency. Full processing capability of mission critical business processes and related infrastructure and people can be restored within an hour. Recovery at an alternate site may not be required (Preston, 1999).
- Level 2 Disaster: Causes moderate outage. An example of Level 2 disaster is LAN failure. Some or all business processes at a location might experience moderate damage. Processes may or may not continue since the equipment is below the minimum capacity to run. Full processing capability of mission critical business processes and related infrastructure and people may be restored within 2 hours. An alternate recovery site may not be required for continuing business but alternate equipment or communication links may be required (Preston, 1999).
- Level 3 Disaster: Causes severe disaster. An example of Level 3 disaster is riots. Infrastructure ceases to function. Full processing capability of all business processes from that location and related infrastructure may be restored within 1-2 days. Use of alternate recovery site will be required (Preston, 1999).
- Level 4 Disaster: Is a catastrophe, such as earthquake, war, or a major terrorist attack. This type of disaster results in major disruption of services. Full processing capability cannot be achieved for a substantial period of time. Recovery will require use of alternate recovery site (Preston, 1999). The following table gives details of these threat levels.
Table 2.1. Threat Level Analysis (Preston, 1999).
Table 1. Four Levels of Threats (Preston, 1999).
A disaster may impact an organization in the following ways (Gilchrist, 2001):
- The organization may not be able to operate from the affected site.
- The organization may lose critical resources, such as systems, documents, and people.
- The organization may not be able to interact and provide services to business partners, clients, brokers, vendors, and other related financial institutions.
- In addition to incurring financial losses, disasters may impact the credibility of the company. In extreme cases, the company may lose many of the clients.
What to Back Up
The question of what to backup is best answered by asking ‘what are the company’s soft assets? An IT company may regard its software source code, its database structure, software source code of its applications as very crucial. For example, a company such as Microsoft would consider the source code of Windows, XP, MS Office and other software applications as critical and would want to ensure that the code is recovered at any point of time.
A banking company would consider the financial records of its customers, its own receivables and credit/ debit records as very important. Banks store the account details, credit card payment and receipt details, information about mortgages and loans, Forex accounts as critical and would be interested in taking the back up of such records. A large investment and share trading company or a bank that deals in futures would consider its stock portfolio as very important.
Government defence bodies would consider details of their troop deployment, state of munitions and aircraft, status and position of different missile systems as crucial to the protection of their country and would want this information to be safe and recoverable at any point of time. So the data to be backed up would depend in what the company feels is crucial and important. Hence the data to be backed up would vary (Toigo, 2005).
Another issue that comes up is the question of data formats and the type of backup. An organization typically stores information either in encrypted form, binary code or in the form of documents such as MS Word, XLS, pdf, image files and so on and these formats have to be saved according to the organization needs. Many organizations, to preserve the integrity of their data systems usually encrypt data using 128 bit or 256-bit encryption. At any point of time during the recovery system, the encryption key should be available to authorized personnel with the required level of clearances (Toigo, 2005).
Different techniques are used for backing up data and these include the incremental back up system that writes only data that has been changed since the last backup. Considering that banks and large organizations have data sizes in the range of Terra Flops, if a daily back up of this huge ream of data was to be taken, then massive resources would be required, time used be excessive and the system would slow down. To get over this problem, incremental data back up is taken and this process ensures that only data that has been changed since the last backup is written in the back up area. Also, since backup slows down the system, company’s run the data backup process as a day end process, late in the night when very few users would be logged in (Hiatt, 2007).
It is worth to remember this statement “When it comes to back up, members of organization are paranoid. While some feel that every little bit of email or document that they have created (which would be probably be deleted by the recipient) has to be backed up, others tend to develop paranoia that their documents or writing would be available for everyone to see and they would not want to share it with others. The management has to step in at a certain stage and frame a policy on what is worth backing and what is best left on the PC of a warehouse assistant clerk” (Kaye, 2006).
Methodologies
The term Methodology refers to the approach taken for the research process, from the theoretical framework, hypothesis to gathering and analysing of data. The term method refers to the various means by which data can be collected and analysed. The methodological assumption is concerned with the process of the research, from the theoretical underpinning to the collection and analysis of the data (Silverman, 2001).
Qualitative and Quantitative Research
Studies that use data cover areas of economic study, unemployment, health of the economy, scientific study, patterns of demography and others. Different type of data is collected using methods such as databases, reliable government studies, secondary research published in peer reviewed journals, experiments, observations, interviews and others. Data that is collected can be designated into two basic categories, quantitative and qualitative.
This also formulates what type of research a study will be conducting: quantitative or qualitative. Denzin (2000) described quantitative research as “the research which gathers data that is measurable in some way and which is usually analysed statistically”. This type of data is mainly concerned with how much there is of something, how fast things are done, and so on. The data collected in this instance is always in the form of numbers. In order to obtain quantitative data, one should have a specific framework about what has to be researched, what should be known, types of inputs that are admissible and so on.
Such an approach can help in designing the questionnaire, make observations and so on. Denzin also defined qualitative research as “the research that gathers data that provides a detailed description of whatever is being researched”. Both types of research have their supporters and detractors and while some claim that quantitative research is much more scientific, others argue that qualitative research is required to examine a specific issue in depth.
Researchers who support that quantitative research argue that numerical data can be statistically analysed and in this way, it can be established whether it is valid, reliable and whether it can be generalized. By using numerical data, these numbers can be used to compare between other studies, which also use the same numbers, the same scales, etc. With qualitative research, it is not so easily possible to achieve this result, as no specific method or scale of measurement is kept.
This is basically the main disadvantage of qualitative research, as findings cannot be generalised to larger populations with a large degree of certainty and validity. The reason that this happens is because their findings are not tested and evaluated statistically in order to establish whether they are due to chance or whether they are statistically significant and to what extent. Another advantage of quantitative to qualitative research is that qualitative research is descriptive and many times subjective too, as it depends on the researcher’s perspective or how the research registers certain behaviours. Another researcher conducting the same study may observe the qualitative data, which is given in a completely different way.
Quantitative research does not show this disadvantage as all the data is in the form of numbers and, therefore, it may be translated in only one possible way, that which is given from the objective value of each specific number. However, qualitative research has many advantages to offer too, which are not offered through quantitative research. It is usually through such type of research that a rich, in-depth insight can be given into an individual or a group, by being far more detailed and by recognising the uniqueness of each individual. This type of research realises the importance of the subjective feelings of those who are studied.
Qualitative research analysis does not have to fall into the pitfall of being ‘forced’ to have all its values into certain numerical categories. It is clear that not all phenomena can always be adequately assigned a numerical value, and when this does happen, they lose much of their naturalistic reality. Qualitative research can simply describe a data for what it actually is without having to assign it to a number. Qualitative research can give attention to occurrences, which are not so common.
For example, it is very difficult to find enough participants to conduct statistical correlations between nations on women being more accident prone and indulging in rash driving because women will not be willing to be used for such studies. In such cases, quantitative research is impossible and it is only through qualitative research that such cases can be examined in depth and conclude to specific findings and results (Byrne, 2002).
Data Gathering
Gathering data is a very important phase and due consideration must be given for the time frame of the research.
Single and Multiple Methods
It is not possible to recommend a single data collection method for each project since each project would have different requirements. In such cases, the use of multiple methods is essential. Multiple methods by using survey instruments, review of documents to understand the project is recommended as it gives a better overview of the data. Such methods also highlight the errors between different methods and the occurrence of bias by a specific method is reduced. In some cases, the use of multiple methods is possible when the project requires large analysis spread across multiple sites. Also, multiple resources require more manpower and resources and these are usually available for larger projects (Denzin, 2000).
Sample Selection
The sample to be researched to a great extent determines the data collection method that is used. Surveys are better suited when used to obtain information from participants, while focus groups would require a different method since the groups are diverse. The sample size would also depend on the project requirements and the group that has to be studied. While considering large number of subjects is best since the results are more reliable, the costs of studying such large samples increase. If the project has sufficient budget allocations, then it is possible to include larger samples and members in the study (Byrne, 2002).
Cost Considerations
Cost is an important aspect for research projects and choosing the method for data collection depends on the budget. For tasks such as running observations, program and project document review can be achieved with lesser costs, but tasks such as the design of the survey instruments, administering the instrument to subjects and analysing the results would need the help of an external evaluator.
In some cases, staff would have to be sent for training. When standard tests and analysis are to be used, some external staff and experts may have to be involved. For storing and archival of data, software would have to be used so that the data can be analysed as required. Since project budgets tend to be smaller in the initial stages, effort should be spent in creating a number of data collection instruments and tools with a view to fulfil future requirements as the program evolves and moves across different phases (Byrne, 2002).
Sample Size
The sample size used in research has always created disagreements and controversies. Various issues such as ethical issues and statistical problems arise and these need to be addressed properly. When very large sample data sizes are used, the ethical issue of wasting resources will arise, while selecting a smaller size will create another ethical issue. When the research objective is large, then a difference that is statistically significant may be observed even with a smaller sample.
However, the difference that is statistically significant may happen when a smaller sample size has been used and such differences do emerge and also when there is actually no difference. Freiman (1970) reported that a study on clinical trials that showed negative results for certain parameters for the effectiveness of a treatment; but after the results were further examined it was found that because of the small sample size, 50% of the results and method used were not adequate to cover 70% of the improvements.
Many researchers when faced with shortage of resources or when they find that bigger sample size is not available or would take too much time tend to use smaller samples in the hope that the size is representative of a wider section of the data. However, in many cases, this is misleading and researchers would be held responsible of major errors that were caused due to ignorance rather than due to misconduct. In research, ignorance does not lead to a researcher being free of misrepresentation charges and such practices cannot be excused (Freiman, 1970).
Describing Data
While gathering data is one part of the research, interpreting data is very important. Different classifications are used to identify data. Variable: A variable is an item of data and some examples include quantities such as gender, test scores, and weight. The values of these quantities vary from one observation to another. Types and classifications are: Qualitative-Non-Numerical quality; Quantitative-Numerical; Discrete-counts and Continuous measures (Silverman, 2001).
Qualitative Data: This data describes the quality of something in a non-numerical format. Counts can be applied to qualitative data, but one cannot order or measure this type of variable. Examples are gender, marital status, geographical region of an organization, job title, etc. (Silverman, 2002).
Qualitative data is usually treated as Categorical Data. With categorical data, the observations can be sorted according into non-overlapping categories or by characteristics. As an example, apparel can be categorised as per their colour. The parameter of ‘colour’ would have certain non-overlapping properties such as red, green, orange, etc. People can be categorised as per their gender with features such as male and female. While selecting categories, care should be taken to frame them properly and a value from one set of data should belong to only one type of category and not be able to get into multiple categories. Analysis of qualitative data is done by using: Frequency tables, Modes – most frequently occurring and Graphs- Bar Charts and Pie Charts (Silverman, 2002).
Quantitative Data: Quantitative or numerical data arise when the observations are frequencies or measurements. The data are said to be discrete if the measurements are integers, e.g. number of employees of a company, number of incorrect answers on a test, number of participants in a program. The data are said to be continuous if the measurements can take on any value, usually within some range (e.g. weight).
Age and income are continuous quantitative variables. For continuous variables, arithmetic operations such as differences and averages make sense. Analysis can take almost any form such as create groups or categories and generate frequency tables and all descriptive statistics can be applied. Effective graphs include Histograms, stem-and-Leaf plots, Dot Plots, Box plots, and XY Scatter Plots with 2 or more variables.
Some quantitative variables can be treated only as ranks; they have a natural order, but these values are not strictly measured. Examples are: age group (taking the values child, teen, adult, senior), and Likert Scale data (responses such as strongly agree, agree, neutral, disagree, strongly disagree). For these variables, the differences between contiguous points on the scale need not be the same, and the ratio of values is not meaningful. Analyse using: Frequency tables, Mode, Median, Quartiles and Graphs Bar Charts, Dot Plots, Pie Charts, and Line Charts with 2 or more variables (Silverman, 2002).
Questionnaire
A structured questionnaire was emailed to the respondents, identified in Table 1.1. and followed up with an interview. The questionnaire is shown as below:
Table 4.1. Questionnaire used for the Research (Questionnaire, 2007).
The instrument had 20 questions that queried important aspects of the DRP and BCP plan and it was mailed to the respondents who completed the instrument and sent it back. Replies to the questions and the analysis are performed in Chapter 7. The first three questions were generic and asked for information about the responder’s organisation. The other questions are specific to the DRP and BCP implementation and ask questions about various features of the implementation.
Corrigendum to Impact of Potential Interruptions for Question 8
The following table is an extension of Question 8. The questions will help you to specify the likely impact on the organisation if a disaster strikes. Type of effect possible is low, medium and high. There are two categories of impacts, qualitative and quantitative and each category has a number of possible impacts. For each impact, you need to specify the possible effect as L, M or H to indicate Low, Medium or High impact.
Table 4.2. Corrigendum for Question 8.
Framework for DRP
This chapter provides a framework for constructing DRP network for IT and other companies that operate across multiple locations. Information for this section has been obtained by field visits and with extensive literature review and observation of actual implementation plans in different companies. The chapter forms one of the important features of the report and would help in practical implementation.
Information is the key to survival for organizations. Information could be stored either electronically or as hard copies. Disaster Recovery Plan (DRP) is a set of procedures designed to restore information systems. A DRP mostly deals with technological issues and also recommends infrastructure that should be implemented to prevent damages when a disaster occurs. A disaster can make the business processes totally or partially unavailable.
Business Continuity Plan (BCP) focuses on sustaining the business processes of a company during and after a disaster and this plan is a continuation of the DRP and cannot be implemented in isolation. A BCP lists the actions to be taken, the resources to be used, and the procedures to be followed before, during, and after a disaster. An IT disaster recovery plan is implemented for an organization in this section (Facer, 2001).
The DRP within a company is responsible for performing the business impact analysis, a process of classifying information systems resources baseline on criticality, and development and maintenance of a DRP. Tasks that need to be covered are included in the BCP document. The DRP should also maintain the BCP document up-to-date. This responsibility includes periodic reviews of the document – both scheduled (time driven) and unscheduled (Event driven).
DRP defines a Recovery Time Objective (RTO) that specifies a time frame for recovering critical business processes. The DRP meets the needs of critical business processes in the event of disruption extending beyond the time frame. Recovery capability for each Strategic Business Unit (SBU) – including all Projects being executed under the SBU – shared service, location and Offshore Development Centre are defined. In the event of any moderate / minor disaster, the recovery capability should ensure that the business processes work seamlessly without affecting any other dependent critical business processes. E.g. If the main power grid is disrupted, there must be standby facilities like generators to ensure that power is available (Facer, 2001).
Hypothetical Company Description
In this chapter, a DRP plan would be implemented for an IT company called ABC Ltd. The plan is based on literature review and actual implementations done at different IT companies and while each company may have its own modalities and priorities, the common elements of DRP are discussed. The following illustration shows how the company is organized.
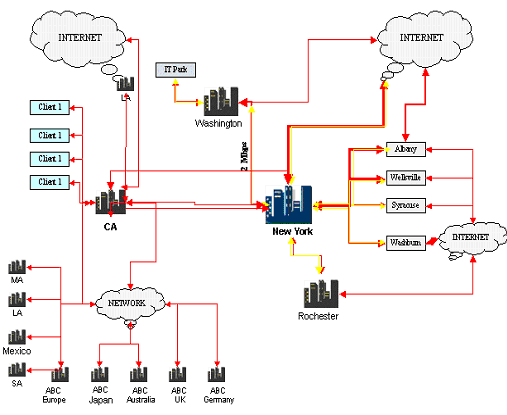
The above figure shows different assets and nodes of ABC company are organized. The company has its head quarters at New York and a number of units in branches in areas such as Washington, Rochester, Syracuse and others. The company also has a number of off shore development centres and these are identified as ABC Europe, ABC Japan, ABC Australia, etc. In addition, the company has a number of clients and these are identified as Client 1, Client 2.
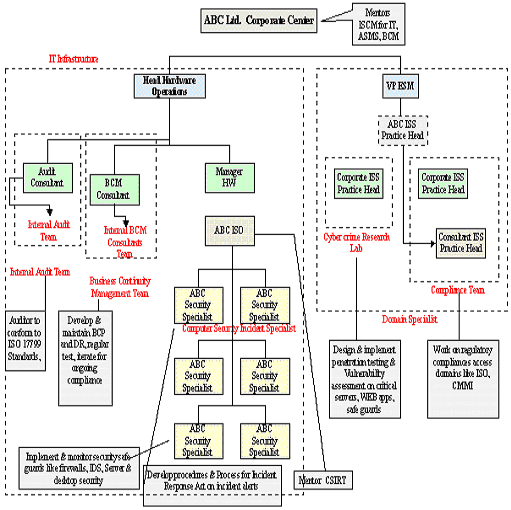
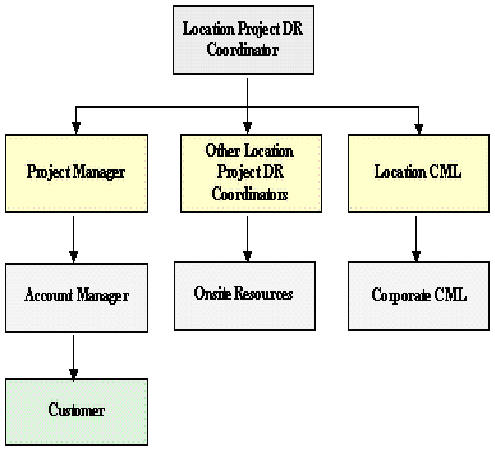
Defining the Organization Chart for DRP
Before implementing a DRP, it is essential that an organization chart be created that would identify key employees who would be members of the DRP team. The following figure illustrates the organization chart of ABC Ltd.
Protecting Intellectual assets with the DRP
In a business relationship, a client invests in internal resources like personnel, funds to set up infrastructure. In addition clients may provide a company with resources in the form of confidential information, raw source codes, initial drawings, machinery. In addition a company, serving its clients has similarly invested funds and other resources in the business engagement. These investments represent assets. Companies must take preventive actions, such as setting up a dedicated security team or formulate policies that help you reduce damage when disasters occur.
IT Team Security Structure
The IT Security Team of a company is responsible for implementing and maintaining the corporate security policy at all ODC locations and other support units. A dedicated Security Officer should be assigned to all the units. In addition, the company needs to conduct security awareness program for all ODCs. Following figure shows a typical IT Security Team structure.
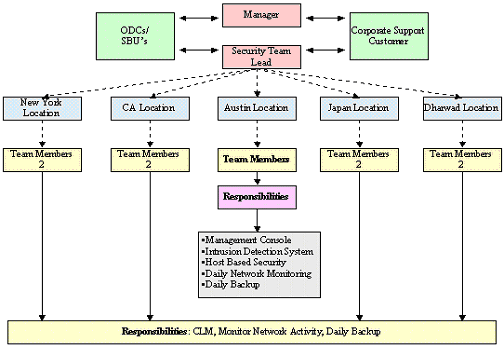
This figure shows the structure of the IT Security Team of a company, ABC, Ltd. The figure shows the various SBUs and their locations.It also lists the responsibilities of the IT security team of the SBU and the centre.
An important point to note is that these teams are expected to only ensure that systems are started and data recovery procedures are initiated. They are not expected to act as application experts for all the running projects and in the event of a disaster. It is the individual project teams that would configure, set up and install their codes and applications.
The DRP Network Diagram
The DRP would need to cover all these units and assets. To allow quick back up and DRP procedures for the company, the following network diagram is proposed.
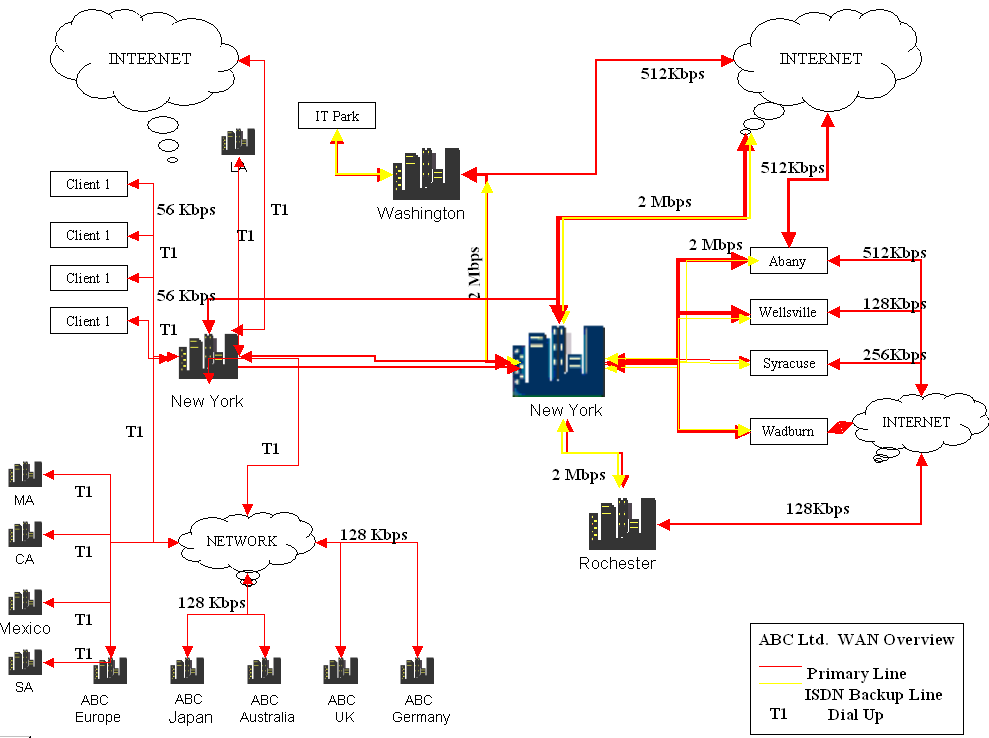
In the diagram, the connectivity is allowed through a primary ISDN Back Up Line and a Dial Up Line. A separate ISDN line for backup is required since the backup process consumes extra bandwidth and may slow down regular business processes.
Based on corporate security policy, all the locations with a direct Internet access/connection should be secured by deploying firewalls. You can have a dedicated team of professionals, certified in various technologies who centrally manage the firewalls. You also need to have a change management procedure that enables you to incorporate any desired change in the existing set-up within a short notice. When a disaster occurs if a backup hardware exists, it can be used in the disaster recovery plan to restore services. You can protect gateways by installing Checkpoint Firewall Modules in the organization Network.
This enterprise wide implementation is managed using a central management console. At each location a De-Militarized Zone (DMZ) must be created to protect important servers. It is also necessary to ensure that the policies installed on the Checkpoint Firewall Modules are based on the corporate network security policies. Precautions must be taken against Internet hacking and vulnerabilities. Vulnerabilities are holes or weak points in the network. Following figure shows a sample firewall installation for a location (Preston, 1999).
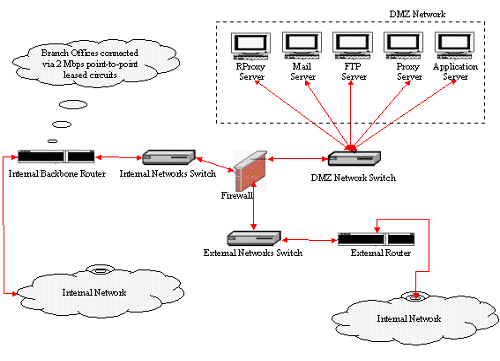
The Firewall would ensure that unauthorized users would not be able to enter the network when back up processes are running or when a DRP plan is being implemented during a disaster.
Steps to Implement a DRP
Developing the DRP involves the following steps (Preston, 1999).
- Risk Assessment
- Business Impact Analysis
- Strategy Selection and Implementation
- Testing
- Maintenance
Next sections provide details of these steps.
Risk Assessment
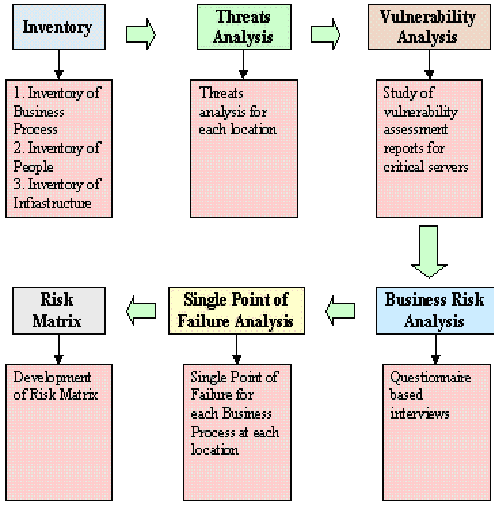
In this phase, risks to the business processes have to be identified along with assessing existing mitigation measures, and recommend mitigation measure wherever necessary. The activities in this phase helps DRP administrators to determine the extent of the potential threat and the risk associated with the IT infrastructure and IT applications of your company. A threat is any circumstance or event that can potentially cause harm to the business. The risk assessment phase involves/includes the following (Hiatt, 2007):
- Inventory: identifies/Documents the various business processes, hardware, software, communication links, documents, and associated people using standard templates developed by the risk assessment team.
- Threat analysis: Identifies various threats to the business processes. It also identifies the probability of a threat being executed and the potential impact a threat will have on the business in the event of its execution. This is done using a standard template developed by the risk assessment team. The risk assessment team identifies a list of over 35 possible threats to any asset. Based on this list each location is assessed for the probability of each threat being executed and the potential impact on the business processes.
- Vulnerability analysis: Scans critical servers and hardware devices owned by the company periodically for identifying vulnerabilities and taking corrective actions based on the audit reports. These reports should be studied for their completeness and adequacy. In addition, while arriving at the probability of a threat being executed, the existing vulnerabilities of each location must be analysed.
- Business Risk Assessment: Includes a detailed assessment of the practices followed by the business units with respect to risk management. The risk assessment team should conduct detailed interviews using standard questionnaires with senior representatives of the business units to understand the risk management practices of the individual business units.
- Single Point of Failure Analysis (SPOF): identifies the most vulnerable business process. A SPOF is the weakest link in a business process. Each SBU must identify the SPOF at their locations.
- Risk Matrix: Analyses the identified risk, derived by qualitative analysis of various threats and vulnerabilities to business processes through threats and vulnerabilities analysis, business risk assessment and SPOF analysis. The risk areas are classified as Very High Risk Areas, High Risk Areas, Medium Risk Areas, and Low Risk Areas. You can also recommend mitigation measures for each risk area identified.
The following figure illustrates the risk analysis for the company.
A number of templates have to be used at this stage to gather information about a project. These would provide micro information at a project level or at a client level. Some templates that need to be used include (Ambs, 2000):
- Template for DRP Resource Requirements: This template is used to gather data for resources that are required to prepare a DRP.
- Template For Project: This template is used to gather data about a project and helps to create a DRP at a project level.
- Template For Project Team Details: This template is used to gather details of the project team members. The data is used to identify key members who may need to be moved to an alternate recovery site in case of a disaster.
- Template For Client Team Details: This template is used to gather data about the client team details. Members identified here can be contacted in case of a disaster.
- Template For Resource Requirement at Project Locations: This template is used to gather details of resources required at the alternate recovery site.
- Template For Project DR Alternate Site: This template is used to gather data for an alternate recovery site.
- Template At DR Location For People And Resources: This template is useful to gather data about people and other resources required at the alternate site.
- Template For Min Required Resources At Alternate Site: This template is used to gather data about the minimum resources required at the alternate recovery site. Details of software and hardware that would be required need to be listed.
- Template For Project Recovery Plan: This template is used to gather data for project recovery.
A sample template is shown below:
Table 5.1. Sample Template for Risk Assessment (Ambs, 2000).
Business Impact Analysis
The overall objective in this phase of the project is to gain an understanding of the business processes and to lay the framework of a business continuity plan for the business units. A Business Impact Analysis (BIA) must be performed with the objective of (Benton, 2007):
- Evaluating the risk to the business due to systems and/or process failures.
- Identifying critical business processes and the associated computing applications.
- Estimating the impact of disruption.
- Defining the recovery time objectives for critical business processes.
Following figure illustrates the methodology used for BIA
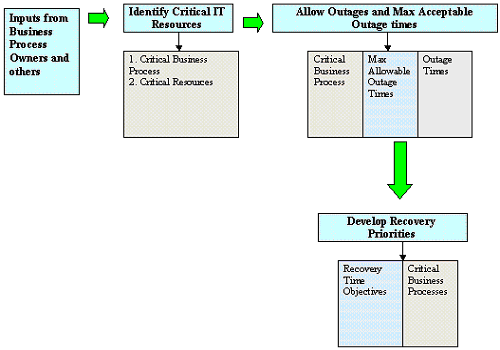
This figure shows the business impact analysis approach. BIA is performed by interviewing business processes owners using detailed questionnaires / templates. The primary areas on which the interviews should focus are (Benton, 2007):
- Identification of critical business processes and critical resources and applications associated with critical business processes.
- Interfaces between various business processes.
- Identification of outage impacts of business function unavailability and maximum allowable downtimes.
- Prioritisation of recovery processes through recovery time objectives.
- The resultant BIA documented for each business process describes the following:
- The outage impact for the business process.
- The criticality of each business process based on the outage impact. The business processes are classified into four levels of criticality – Mission Critical, High Criticality, Medium Criticality, and Low Criticality Business Process.
- The minimum human resource required sustaining the business process during a disaster.
- Criticality of locations from where the business processes are executed.
- Criticality of the IT infrastructure that support the business processes.
- Existing recovery times for the business processes in terms of hardware acquisition time and software installation time.
- Recovery time objectives for the business processes depending on the criticality of the business process.
Strategy Selection and Implementation
Based on the risks identified in the risk analysis phase and the RTO defined in the BIA phase, strategies are identified to adequately mitigate the risks and satisfy the RTO. The strategies included – for each business process and associated resource is (Margaret, 2007):
- Infrastructure Strategy: Includes hardware, software, and networking redundancy.
- Alternate Site Strategy: Defines the alternate site from where the business process will be recovered in case of disaster.
- Equipment Strategies – Ensures availability of necessary equipment at the alternate site.
- People Strategies – Ensures availability of critical personnel during at the alternate site. E.g.: Specialized software’s like databases, operating systems need skilled people who know what needs to be done to get the applications running quickly.
- Other Strategies – Handles insurance, service level agreements, and annual maintenance contracts to transfer risks that cannot be mitigated directly.
In order to tackle the operational contingencies for a large organization, the BCMP outlines the BCP concept of operations. The concept of operations is based on the risk mitigation strategies identified by the BCMP and approved by the corporate centre.
DRP – BCP Structure
Based on the size, geographical spread, and complexity of the organization structure, the DRP is divided into individual BCP for the various SBUs. Each SBU, shared service, and location. The location BCP covers the infrastructure and support functions for the location, whereas the business unit BCP covers the SDLC – Software Life Cycle Development Cycle, for all projects executed from the SBU site. The shared services BCP include the continuity plan for support services, such as finance, accounts, and human resource. Depending on the type and extent of the BCP event, relevant BCP is invoked. Following illustration gives the BCMP structure for a company (Pfleeger, 2002).
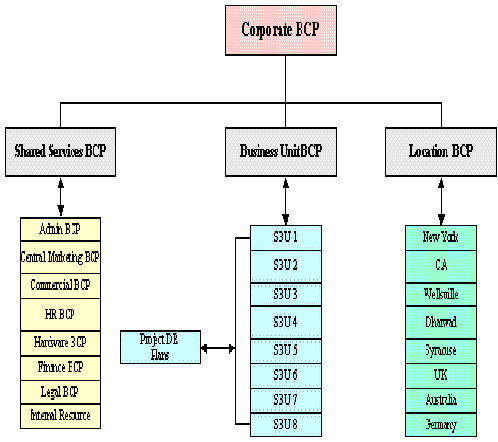
Crises Team Management Structure
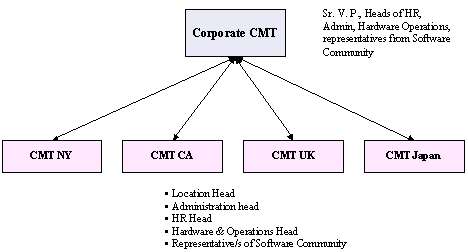
Each BCP identifies a Crisis Management Team (CMT) that will take charge of respective operations in the event of a disaster. The composition of the various Crisis Management Teams is depicted in the following figure (Swartz, 2004).
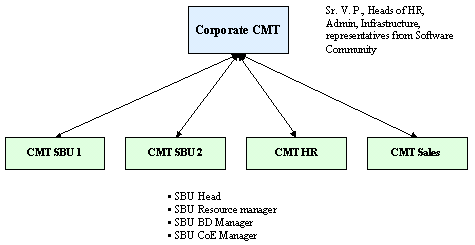
At this point of time, it is essential to have a CMT for business units also. These are illustrated as below:
Process Flow to identify disaster and activate DRP
Communication lines should be established that follow guidelines for reporting and managing disasters. The process flow diagram shown in the following describes the various stages of reporting a disaster.
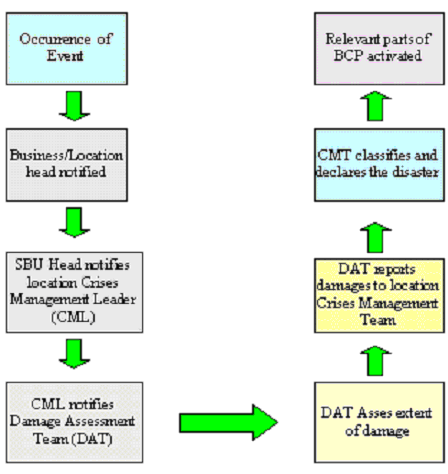
The CMT may decide to activate some BCP procedures even before the DAT reverts back to the CMT with the Damage Assessment Report. This ensures that in case of a severe disaster, business processes, having a low recovery time objective, are activated immediately without awaiting a detailed assessment of the extent of damage.
DRP Invoking Procedures
DRP activation depends on the level of disaster. The BCP documents the following procedures during a disaster (Preston, 1999);
- Procedures for invoking relevant BCPs
- Procedures for communication of disaster. This includes procedures for –
- First notification of disaster and further escalation to CMT.
- Notification of disaster to SBU heads
- Notification of disaster to employees
- Notification of disaster to customers
- Notification of disaster to Media / media Management
- Procedures for Emergency Evacuation including Roles and Responsibilities of various personnel involved in Evacuation
- Recovery Procedures for various Infrastructure Items and IT Applications
Project Specific Disaster Recovery Plan
Each Project should prepare a DRP before the start of the Project in pre defined templates. Each Project Disaster Recovery Plan identifies an alternate site from where the project will be executed, in case the primary location is inaccessible based on the requirements of the project and availability of infrastructure at alternate site. This information is available from various templates that are used in the risk assessment (Toigo, 2005).
- The Plan should identify critical project team members who will be shifted to the designated alternate location in case of such an incident. Where an employee may need to travel to onsite locations during a disaster, travel and other necessary documents are kept ready.
- Data backup for all Projects should be stored at a predetermined location.
- In case of a disaster where the primary site becomes inaccessible, each SBU from that location communicates requirements to the CMT to shift project team members.
- CMT facilitates transportation of key employees to alternate locations through the Administration department.
Notification Procedures
A structure to notify disasters should be in place. This structure is also called as call tree. A call tree to notify occurrence of a disaster is shown in the following figure.
The figure shows the structure used to notify affected parties about the disasters. Emergency Procedures For Project DRP are
- Control will be transferred to on-site – if required.
- If recovery is required from alternate location, acquire resources / infrastructure from CML.
- Initiate process of recovering processes, data, and applications as per the RTO or identified priority.
- Make arrangements for transportation of people (as identified in Project DRP)
- Resume operations at alternate location.
- Confirm all Mission Critical services are restored
- Use call tree to notify affected parties that services have been restored from alternate location.
- Take control back to off-shore
Testing
Testing helps to evaluate the ability of recovery staff to implement the plan quickly and effectively. Each element of the BCP and DRP should be tested to confirm the accuracy of individual recovery procedures and the overall effectiveness of the plan. Plan testing is designed to determine (Pfleeger, 2002):
- Whether the recovery teams are ready to cope with a disruption
- Whether recovery inventories stored off-site are adequate to support recovery operations
- Whether the business continuity plan has been properly maintained
Test Plan
Before conducting the test, a detailed test plan should be developed. The test plan includes (Pfleeger, 2002):
- Scope of the Test – Defines the boundaries of the test. For example it lists the location, area, projects, components, and data.
- Test objectives.
- Test Scenario – This includes
- Type of Test – For example Structured Walkthrough Test, Component Test or Full Function Test
- Test Schedule
- Description of the Test Scenario
- Success Criteria For the Test – including the method used to evaluate the test results.
- Test Participants
- Sequence of Activities
In addition, maintenance procedures should be implemented for the DRP. To prevent Level 1 incidents of virus and hacking attacks or due to improper behaviour of employees, a security policy should also be implemented. The policy would specify rules of conduct while working, rules for email, data storage, personal storage devices such as iPods, MP3 players, mobiles with cameras and others.
Maintenance
The DRP must be maintained in a ready state that accurately reflects system requirements, procedures, and policies. IT systems undergo frequent changes because of changing business needs, technology upgrades, or new internal or external policies. It is important to review and update the BCP regularly to ensure new information is documented and contingency measures are revised if required. The DRP team is responsible for maintaining the BCP. The plan defines 2 types of maintenance, scheduled and unscheduled maintenance and these are briefly discussed as below:
Scheduled Maintenance
Scheduled maintenance is essentially time driven and occurs as a result of a scheduled review of the BCP. The frequency and type of reviews that need to be performed to maintain a business continuity plan include:
Quarterly Reviews
People-related elements of a business continuity plan become outdated quickly, quarterly reviews of these portions of the plan are important. People-related elements include:
- Recovery Team Contacts
- Critical Personnel
- Vendor Contacts
- Employee Lists
- Emergency Phone Numbers
Semi Annual Reviews
Strategy-related elements of a business continuity plan are subject to changes in business and technology. These elements should be reviewed on a semi-annual basis. Strategy-related elements include:
- The Strategy Outline
- Interim Strategies
- Prevention and Mitigation
- Resources Requirements
Annual Reviews
The complete BCP should reviewed at least annually. The Business Continuity Management Team should meet with the management to discuss the BCP and obtain formal written approval for the same.
Unscheduled Maintenance
Unscheduled maintenance is event-driven. The Business Continuity Management Team must be made aware of all business-related events that occur which may affect the business continuity plan. Items which may cause unscheduled maintenance to the plan includes:
- Changes in operating system environments (upgrades, new operating systems).
- Changes in the network design
- Changes in off-site storage facilities
- Acquisition of, or merger with, another company
- Sale of existing business
- Re-engineering of a critical business process
- Launch of new products
- Transfer of business functions between existing sites
- Implementation of new business functions
- Discontinuance of an existing business function
- Consolidation of work functions
- Outsourcing of work functions
- Migration to new technical platforms
- Migration to new systems applications
- Migration to new systems hardware
- Change in critical third party vendor/ suppliers
- Changes in telecommunications devices/systems, voice or data, structure/ equipment. These may include EPABX, new telephone systems.
- Transfer, promotion, or resignation of individuals on the emergency notification list or CMT/DAT/Recovery Team members.
Training
Training enables you to plan for deficiencies to be identified and addressed. Training helps conduct mock BCP test drills, keep BCP personnel recovery aware, and identify potential weaknesses in the plan.
- The BCMP conducts training seminars addressing business continuity in general, and the BCPof the company on a regular basis. The objectives of business continuity planning training are:
- Train employees and management who are required to help maintain the business continuity plan.
- Train employees and management who are required to execute various plan segments in the event of a disaster.
- Increase business continuity planning awareness for those employees not directly involved in maintaining and/or executing the plan.
The following guidelines should be used for training personnel on BCP.
- Training on the BCP should be provided at least annually.
- New hires having BCP responsibilities should receive training shortly after they are hired.
- Training goal should include training personnel to execute the BCP. This will involve the following kinds of training:
- Recovery procedures training
- Business process training
Recovery personnel should be trained on the following plan elements:
- Purpose of the plan
- Cross team coordination
- Reporting procedures
- Security requirements
- Team specific recovery procedures
- Individual responsibilities
The Project Managers and BDO’s should be trained on
- Purpose of the Project DR Plan
- How to identify criticality of the Project
- How to complete the Project DR Template
Security Policy
Internet connectivity and e-mail facility are major productivity tools. They can also be misused or subverted to damage an organization network. Companies must formulate policies to regulate information access, e-mail usage. The next section present the security policies that are actually implemented in one of the surveyed organisations.
Information Security Policy
The information security policy for employees and users is given in this section.
- Employees and authorized non-company employees should be allowed to appropriately use computer resources in ways that will accomplish company goals and initiatives. Users should act ethically and professionally wherever and whenever the resources are used. The use of computer resource must comply with all applicable policies and procedures including code of business conduct, human resource policies employee handbooks, non-disclosure agreements and applicable laws.
- Each user must be aware of the provisions of this policy before being given access to computer resources.
- Ensuring compliance with the procedure, (user-id, password, or any other device issued for accessing company resources remains confidential and under your control) whenever an information system or network is being developed, used, maintained or changed.
- Accessing only relevant information you need to do your job. Employees should note all data including email and data files stored or transmitted is the property of the organization. To properly manage this management reserves the right to examine all data stored in or transmitted by these computers. Computers must be used for business purposes only and employees should have no expectation of privacy associated with these.
- Use only authorized connections to company networks and computers viz. refrain from using devices such as modems, with out prior approval from network security administrator.
- Avoid installing or downloading software from external / internal sources for safeguard against virus infection, if need be scan the same using authorized ant virus software before downloading.
- Report any security breach to concerned manager or network security personal.
- Minimize the use of Extranet; email and other resources for business use only, unless prior approval thru concerned authorities have been taken.
- Passwords are vulnerable to many forms of technology attacks such as cracking programs, network sniffing etc. because of this reusable passwords should not be used for authentication as they provide minimal security.
- Internet/HTTP use is restricted for business use only. During working hrs. (9:00AM – 6:00PM) only authorized users have access to this, users should close browsers when finished with their work in order to avoid misuse. Internet Access is opened for all after office hrs.
- FTP use is allowed for authorized users only and this is restricted.
Information Handling
All data physically sent from the organization whether written or in storage form (e.g. magnetic media) should be securely enclosed and marked Proprietary and confidential.
- No personal data should be brought in or taken out in any storage form from company premises.
- All the written information in form of a FAX transmission or a print out should never be left unattended.
- Unauthorized use of Modems is strictly prohibited in the network.
- No dial-in / dial-out is allowed in the network without prior approval.
- Security administrator should be informed of any activity that could compromise security of the network.
- All office waste that could contain data should be destroyed by means that ensures that the data is irrecoverable (e.g. Shredding).
- Where information is identified as confidential, Proprietary or Commercial in nature, it should not be left in open view.
- When the employees are not at their work desks, confidential information should not be left in the open.
- Visitors should not be allowed to access any information lying on the desk or computer.
- Boot password should be enabled on desktops.
- It is recommended that all Personal Computers should be protected from misuse by using password protected screen saver.
Information Sharing
Information should not be shared with directory sharing on the machine. If needed restrictions in form of password protected shared folders should be used. Blank fields should not be used as the password.
- Data on productivity metrics, commercial terms and price structure should not be shared.
- Information transmittable or accessible through the organizations resources might be sensitive, restricted.
- Where information which is the property of the organization. is required to be sent outside, it should be marked Proprietary on the front cover and where possible, all pages containing data.
- Password protection should be enabled for shared folder.
- Global rights should be removed in WIN/NT and user specific rights should be given.
- Accounts should not be shared with other Users.
Viruses
Virus-infected software should not be released to other users or customers knowingly. All Virus infected software should be brought to the notice of the hardware department. Good Antivirus software should be installed on all desktops with an auto-update feature.
Antivirus software installed on the machine should not be uninstalled without authorization. Reboot should not be done with a floppy disk in the drive. Every disk that has been used elsewhere must be scanned. When disks are infected, hardware department should be informed. Write-protect all utility disks and program disks.
Passwords
- Divulging passwords should be an offence.
- Users should not be allowed to break into other accounts
- Users should not be allowed to attempt cracking of others password
- Passwords should be changed periodically.
- Do not disclose passwords to others
Email Use Policy
- Email facility provided by the organization is a privilege and not a right.
- Purpose: This policy statement provides specific instructions on the ways to secure electronic mail (e-mail) resident on personal computers and servers.
General Principles
- Correspondence via e-mail is not guaranteed to be private.
- Use of e-mail may be subject to monitoring for security and/or network management reasons. Users may be subject to limitations on their use of such resources.
- Fallback and Backup policies are well designed, documented and tested to provide maximum up time
- Users in HR and Marketing department (need to communicate with free mailing domains) are provided mail ID’s on a separate mail server.
- Managers are provided with ID’s on a different mail server.
- Maintenance schedules will be carried out after prior notifications only.
- Rules For Restriction On Size Of Message
- Up to 100KB while sending/receiving messages to/from the Internet
- 1 MB or 3 MB while sending/receiving messages to/from a client site.
- This is subject to prior permission from the hardware department. The project manager should send an email to hardware department ([email protected]) for the same.
- 3 MB for sending messages to anywhere in abcltd.com domain
Following Activities Are Strictly Prohibited. Users shall not
- Spend an unreasonable amount of time on personal e-mail.
- Use e-mail for any illegal purpose.
- Send company-wide virus alerts. Please forward any such information to IT staff ([email protected]), so that appropriate action could be taken.
- Make or post indecent remarks, proposals or materials.
- Transmit commercial software or any copyrighted materials belonging to ABC Ltd. Or parties outside of the company.
Reveal or publicize confidential or proprietary information that includes, but is not limited to
- Financial information.
- New business and product ideas.
- Marketing strategies and plans.
- Database and the information contained therein.
- Customer lists.
- Technical product information.
- Computer/network access codes.
- Business relationships.
- Under no circumstances user will send mails to dummy accounts (e.g. [email protected]) for project testing purposes, because these type of non-existence ID’s create a lot of load on the server.
- Mailing system is for Official usage only. Mails should not be sent for mass mailing of personal information like invitation to parties etc. and relaying to free mailing domains is strictly prohibited.
- Under no circumstances, users are allowed to save a copy of their mails on the server. This consumes a lot of disk space on the servers making maintenance schedules tedious once.
- Use mail servers for storing their personal data backups. Telnet and ftp services to mail servers are prohibited.
- All violations of these policies can be traced to an individual account name and will be treated as the sole responsibility of the owner.
- The above policies are subject to change without prior information to the employee.
Summary
The chapter has discussed in detail the framework of DRP for an IT company that may operate through multiple locations. A specific organisation chart and steps to be followed for DRP implementation have been presented. To protect the intellectual assets of DRP, a company first needs to have an IT team security structure defined, carry out the risk assessment and perform the business impact analysis.
The next important step is to select the strategy for DRP implementation and form the crises tem management structure and create the process flow to identify disasters and activate the DRP along with the DRP invoking procedure and create project specific disaster recovery plan and the notification procedures. Once the DRP is in place, it is important to create a testing plan and a maintenance plan so that the DRP is in a state of readiness. This chapter is expected to serve as a guideline for organisations and managers who would want to create a DRP for their organisation.
Framework for BCP
This chapter provides a framework for constructing DRP network for IT and other companies that operate across multiple locations. Information for this section has been obtained by field visits and with extensive literature review and observation of actual implementation plans in different companies. The chapter forms one of the important features of the report and would help in practical implementation.
A Business Continuity Plan – BCP ensures that after a disaster has occurred and the DRP is running, the business is able to recover and start functioning. BCP is not implemented in isolation but would work along with the DRP and comes into effect after the DRP is implemented. Many clients insist that IT vendors should have DRP and BCP implemented before they provide them with business and work order. This is done to ensure that in the event of a disaster, the client does not suffer huge losses when large amounts of crucial data and source code are destroyed. Though the vendor also suffers losses, the loss to clients is much more since they would be using the software code costing a few million dollars to run their own enterprises worth billions of dollars.
In this chapter, a discussion has been done for three different scenarios: Scenario 1 where a natural disaster such as a hurricane or earthquake has occurred; Scenario 2 where the secure lines and VPN network has been compromised and Scenario 3 where hacking or a very dangerous virus attack has occurred. These three scenarios are Level 4 threats where the business has been severely and critically compromised and there is no chance of the company starting normally immediately. Detailed information of these scenarios was obtained by visiting clients and through email and telephonic interviews.
BCP plan is intended to provide a framework within which companies can take decisions promptly during a business disruption. The objectives of this plan are (Broder, 2002):
- To identify major business risks.
- To proactively minimize the risks to an acceptable level by taking appropriate preventive and/or alternative measures.
- To effectively manage the consequences of business interruption caused by any event though contingency plans.
- To effectively manage the process of returning to normal operations in a planned and efficient manner.
- The scope of the corporate business continuity management plan document must include plans for restoring:
- SBUs and all the Projects being executed by the SBUs
- Shared services
- Information Systems at all locations of the company
Scenario 1 – Natural Disaster, Earthquake, Hurricane
Natural disasters can occur at any point of time and while hurricanes give some amount of warning time, earthquakes can occur instantly and catch IT teams unawares. When such disasters strike, the whole infrastructure such as buildings, servers, computers, network wiring and others may be completely devastated. A disaster is defined as an event that causes interruption of business operations for an uncertain period of time. In this case, an IT company called ABC Ltd. has been considered.
About the Company ABC Ltd
The company has several Strategic Business Units (SBUs) or profit centres that are spread all over the world. The company provides services to various overseas clients through support units, such as offshore development cells (ODCs), onsite personnel, and sales offices (Botha, 2004). Figure 1 shows the organization structure of a company, ABC Ltd.
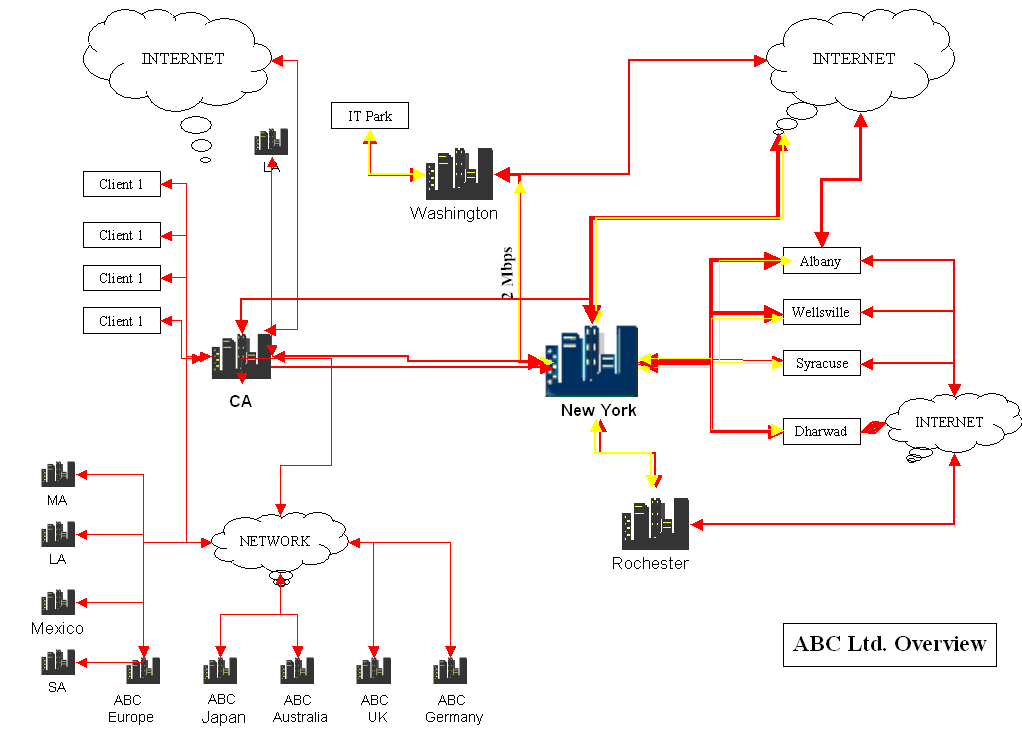
The figure shows the interconnectivity between different units of the company. The central hub of the company is in New York. It is a B2B central server and serves as the communication gateway and database for all business related protocols, processes and storage areas networks and others. The central hub also serves as a Gateway for different clients that the company provides services for and these are identified as Client 1, Client 2, etc. The Network is connected to a number of strategic business units in continents such as Europe, Japan, Australia, UK, Germany, etc. These centres are identified as ABC Europe, ANC Japan, etc. The clients are serviced through a network with different strategic business units (Edwards, 2006).
BCP Scenario
In the scenario, we will project that a major Hurricane has broken out along with an earthquake in the regions in which ABC Ltd. is situated. The natural disasters have taken out all the fiber optic cables and other infrastructure. The intellectual property of the company, its database containing records of transactions, software applications, customer financial records, etc, is stored in the IT systems. If the IT systems are not recovered in time, then all business would cease, people would not be able to use credit cards, personal identification authentication systems would be lost and there would be utter chaos (Edwards, 2006).
For the sake of the paper, it is assumed that a Level 4 disaster has stuck the centers.
BCP Solution
The Business Continuity Management Program (BCP) within a company is responsible for performing the business impact analysis, a process of classifying information systems resources baseline on criticality, and development and maintenance of a BCP. Tasks that need to be covered are included in the BXP document. The BCP should also maintain the BCP document up-to-date. This responsibility includes periodic reviews of the document – both scheduled (time driven) and unscheduled (Event driven). BCP defines a Recovery Time Objective (RTO) that specifies a time frame for recovering critical business processes.
The BCP meets the needs of critical business processes in the event of disruption extending beyond the time frame. Recovery capability for each Strategic Business Unit (SBU) – including all Projects being executed under the SBU – shared service, location and Offshore Development Centre are defined. In the event of any moderate / minor disaster, the recovery capability should ensure that the business processes work seamlessly without affecting any other dependent critical business processes. E.g. If the main power grid is disrupted, there must be standby facilities like generators to ensure that power is available. (Edwards, 2006)
The Proposed Solution
The following network is proposed for the BCP solution.
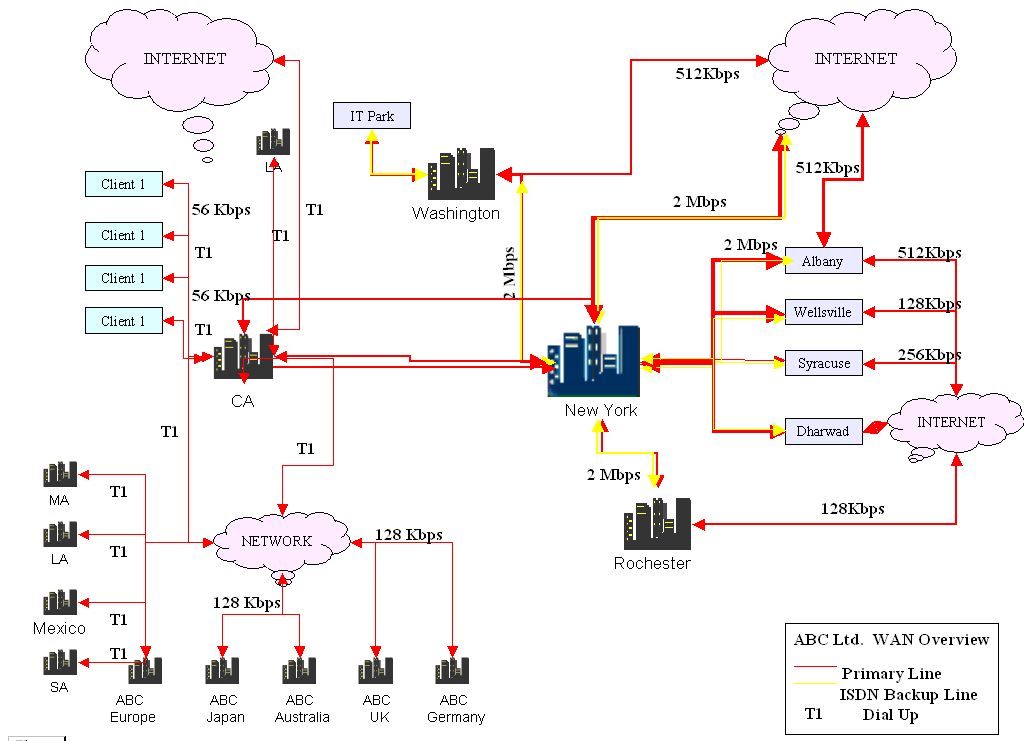
A redundant connectivity network has been proposed between different nodes in the network. According to the plan, a number of mirror cache sites have been proposed and these would take updates from different servers and while transferring the information in the network, they would also store data in storage area networks. A 2 mbps primary line with dedicated fiber optic cabling is proposed for the connection between the central server and the mirror caches. In addition there would be a ISDN back up line that would connect the systems and this would be operated at 512 kbps.
Further connections would have a T1 Dialup connection at 28-156 kbps. The update between the serves would be done at 12.00 hours GMT and at 24.00 hrs GMT. In this manner, even if disasters would take out one whole continent or even the central server, there is sufficient redundancy to start the network at reduced speeds. The data would already be stored in storage data networks and it can be physically retrieved and restored.
Scenario 2 – Secure Lines/ VPN Network Compromised
In this case, the same company as covered in the previous section has been considered. In this scenario, we will assume that the Site to site VPN connectivity from one of the centres ABC Ltd. New York has been compromised by fire. The fire has engulfed the IT systems in the centre and it would be cut off from the rest of the network. (Crothers, 2003). The following figure shows the existing Site-to-Site VPN Connectivity to ABC Ltd. NY.
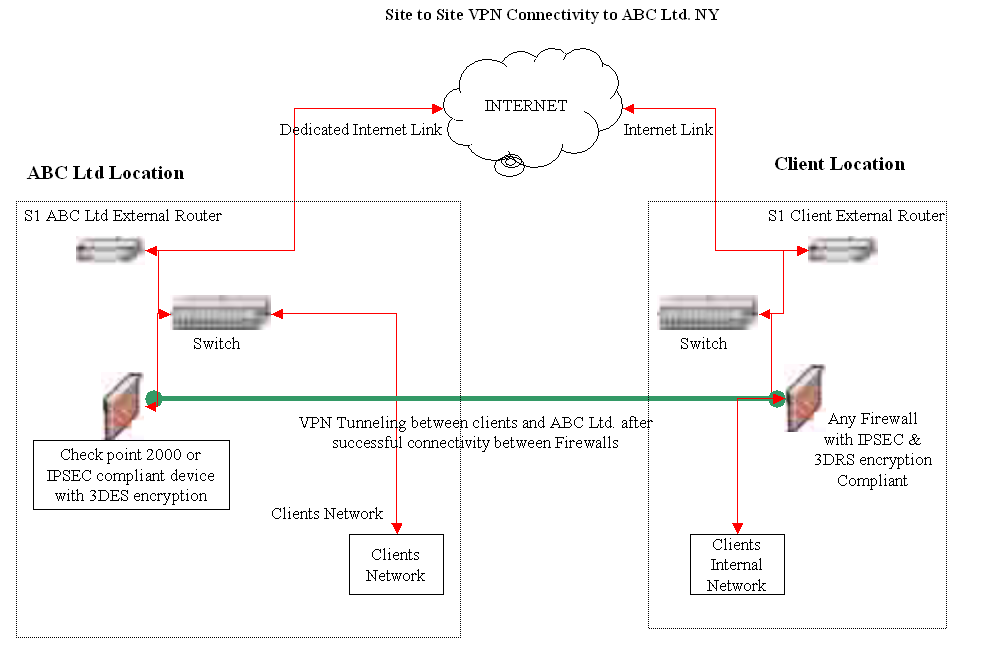
BCP Solution
The following solution has been proposed to get the operations started once the fire has been doused and the network is ready for recovery.
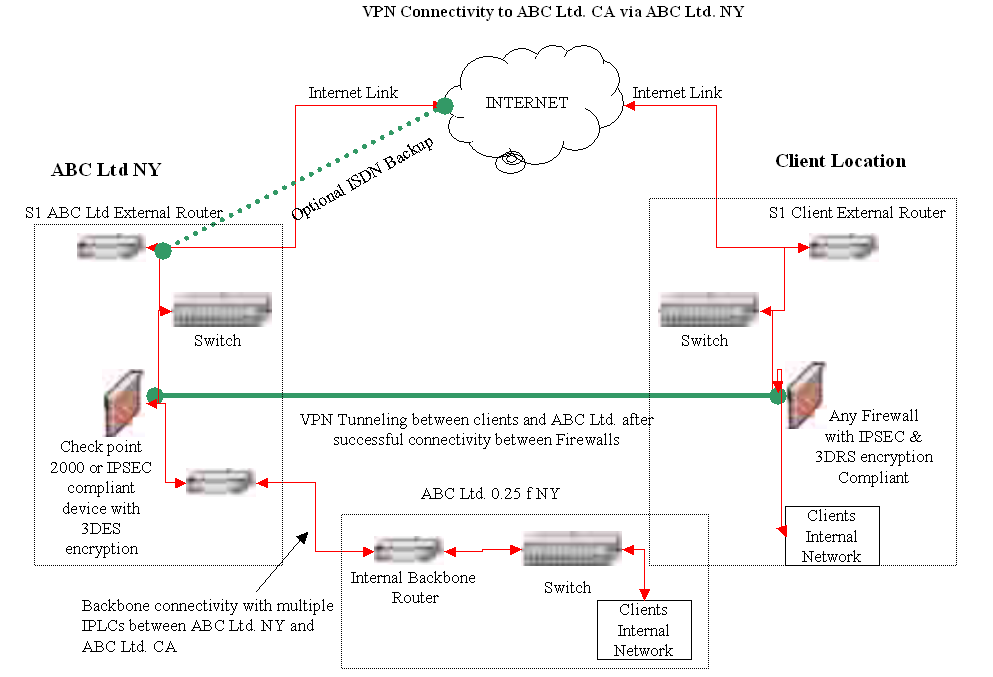
The network diagram as shown above is designed to provide a redundancy between ABC Ltd. NY and the client location. An optional OSDN backup line is proposed along with firewalls. An internal Backbone router has been proposed with a switch that would be connected to the Client Internal network. A fire fall has been proposed of either Checkpoint 2000 or IPSEC complaint with 3DES encryption. The system data is stored in storage area networks and allows for quick restoration in the event of a fire. The fibre optic networking would be designed for Class IV fires and suitably hardened (Lavell, 2004).
Scenario 3 – Hacking and Virus Exploit
A network security administrator has seen in the system log, a few attempts by unauthorized users who have tried to login to the system. The system administrator has terminated the login attempt manually a few times, but there are fears that the hackers will ultimately hack into the servers and compromise the system. The plan is to build a honey pot to trap the intruder and harden the system by using firewalls and proxy servers. This will help in not only trapping the hackers but also allow the network to be recovered in case they hackers damage the network before the intrusion is detected. The BCP will also stop data from flowing out to the hackers (Botha, 2004).
About Hacking and how it is done
Hackers employ a variety of means to bypass your server security. Their main goal is to find an inadequately guarded port and attempt an entry. All computers have ports, where any application or package that you are running, hooks on to your operating system. There are more than 65000 virtual ports on your computer. Hacker, gains access through one of these ports, which are not blocked by an application.
There are many hacking tools, each of which uses a specified port to gain entry. Once in, then the hacker can use system administrator’s rights, go through confidential data like source codes, sales information, financial data and either mail them to himself or corrupt and delete them. Some hackers also deface your website and leave crude messages.
Some ‘good’ hacking tools are: Back Orifice, BOpeep (www.cultdeadcow.com), Tribal Flood Network or trinoo (trinoo), Whisker (rainforestpuppy), Rattler (wyrmsoft), BOred, Silk rope (www.netninja.com). www.sourceforgenet.com is a good repository for the latest versions of hacking tools. These tools are available free along with detailed instructions on their use! All you need is skill and practice to use them effectively. Many online hacking communities offer free peer-to-peer ‘advice’ and ‘troubleshooting’ tips.
If a port is blocked by a legitimate application (for ex Win 2000), the tool will file a counter claim with the BIOS and try to get its ‘right-of-name” registered’.
In the virtual world of hacking, there are the bad guys – Black hats and the good guys – White hats. The black hats are the hackers. There is a constant cops-robbers game fought on-line. An amateur hacker is called as ‘Kludge’, a derogatory reference to someone who uses crude methods and gives up easily. He will bludgeon in clumsily and make a mess. He can be stopped.
It is the ‘script kiddie’, who is far more dangerous. You will realize too late that something has happened. The white hats build ‘Honey Pots’ a false server built to entice and study the ways of the black hats. The honey pot is not for trapping a hacker; in fact, the hacker never realizes that he has been probing a false server. Hopefully, the knowledge gained during the encounter, will help to build better systems.
A hacker first gets into a server by using the automated response and scans for the thousands of IP addresses and accessible ports. He may spend hours remaining connected and cracks the Domain Name Server software.
Then he downloads some sniffer hacking tools on one PC and gets to the root directory. Then he adds a couple of identities or false user names for front door entry and scans the shell account for passwords identities etc. He sends a ‘buffer over flow’ command to confuse the server into revealing all the details and to execute unauthorized commands.
Then he connects to another PC and using the false names, downloads his hacking tools.
The server has log files, which always list details of the traffic. He now attempts to erase the log files and may even replace it by his own. He has now gained entry and will remain quite for minutes or weeks.
This done, he downloads core hacking tools like trinoo or back orifice. If you have detected his antics, you can try to eject him or disconnect your system. If you have never realized that you have a hacker residing in your system, it is dangerous.
Your server will be turned into a zombie and will obey the hacker’s commands and he can hack into anyone who connects to your server. Infection target dates like 15th Aug or 4th July etc can be set.
If your server security is pathetic and the hacker has used very advanced tools for hacking, then he can be accused of ‘Overkill’, which is a black mark against him in the close-knit hacker community.
Logging and auditing on servers, perimeter router should be monitored regularly for any unusual activity. Every important server after being strengthened is scanned for any vulnerability along with the application installed on it before the server is made available to the users.
You can also monitor and restrict access to hardware devices, such as routers. For secure remote access to on-site engineers, marketing officers, and traveling executives, you can set up a Virtual Private Network (VPN), based on IPSEC standards. To effectively administer firewall authentication, you can implement various policies, such as Comprehensive Disaster Recovery, Backup, and Change Request.
All firewall logs are monitored using Checkpoint LOG Viewer. You must take a backup of these log files every day for future reference. You can configure alert messages on each Firewall Module for specific conditions, based on Policy settings and direct these messages to the console for appropriate action.
Security Loop Holes
Security loopholes are certain flaws in the code that may allow hackers to gain access to the application. These security loopholes do not prevent the program from functioning properly and may not even reduce the performance but they are a very serous means that allow hackers to gain access. This section provides a list of some security loopholes that various IT managers in the companies surveyed have provided.
Intrusion Detection Methods and Tools
Hackers can enter your network through unauthorized ports. To prevent such access, you need to implement intrusion detection tools, such as Alert Plus, APA, ARMOR, BlackIce, Cisco Secure IDS, CyberCop Monitor. These tools constantly monitor the network and detect any hacking attempts.
You must have well-documented security and intrusion detection policies, programs, and guidelines to tackle such incidents. You can use the checkpoint log viewer to monitor all firewall logs. You also need to configure alert messages and specify the notification process.
Alerts are e-mails sent by your security system to the system administrator and give a summary of connections made by users. Details include IP number of machines, connection requests made by them and other details.
Physical Access Controls
One method of physical access control to network resources is to issue photo identity cards to every employee at all locations. The identity card may contain magnetic strip to swipe for verification or finger print authentication as part of the security system before the employee enters the location.
You can restrict access to the premises by allowing only those employees working on the projects for the unit or visiting it for official purpose with the required authentication or escorted by an authorized person from the unit. All support personnel are also required to follow the same security procedures.
Virus Detection Capabilities
Networks must be protected with reliable anti-virus software placed on the gateways. You can route all SMTP packets to these anti-virus gateways after being allowed access through the perimeter devices such as protos-snmp-tool, X-Force This method of virus detection helps you filter E-mail viruses.
Ensure that individual desktops and servers should have anti-virus software installed. All the desktops must be automatically updated for latest virus signatures using a server at each location.
The anti-virus application should be capable of allowing you to deploy from a single machine, updates, upgrades and security policies to all machines in the network. Anti-virus applications like eScan (www.mwti.com) offer this feature.
Encryption Capabilities
3DES is the preferred encryption standard. All management access to firewall servers must be encrypted by 3DES. DES and 3DES Encryption Standard should be used between firewall modules for VPN. Secure Client Software should be used for remote access for additional security. For specific services, such as HTTP, SMTP, and FTP services, user authentication should be enforced.
Scanning
Entire network must be scanned monthly and Audit trails must be maintained to enhance security within the network. For all new locations, penetration testing using tools such as Mingsweeper, Nmap, SmartWhois, SamSpade, SolarWinds and Internet Scanner must be done. These tools probe communication services, operating systems, applications and routers to uncover and report system vulnerabilities that might be open to attack.
Apart from this internal activity, an independent third party vendor should be hired to perform audits. The company should follow a procedure of auditing the security measures at least every six months. You can have an independent third party vendor audit the security measures. The audit should include physical audit, vulnerability assessment, and penetration testing. The audit reports must be sent to the management.
Authorized Access To Hardware And Client Data
All workstations in the network must be protected by boot password and network login id and password. The Systems Operations department issues the boot password and the network logon information, upon receiving a written request from the respective manager. The network login id and password allow access to the members of a specific unit.
The systems operations department maintains all the software, owned by the company. The system operations department, on receipt of a written requisition, authorized by a manager carries out the software installation in the company. You must also ensure that no magnetic media, such as floppy discs, tape cartridges is carried inside or outside the company premises without authorization.
You must store any customer supplied software and documents under lock and key. You are also responsible for setting up access controls to prevent unauthorized copying or modification of such software.
Segregating Client Data and Projects
The client data and projects must be segregated through isolation of networks and physical facilities at the ODC. Major customers may be connected to the company through LAN and WAN. You must also ensure that the LAN and WAN segments for all major customers should be segregated. The segregation process regulates all traffic coming in and going out of the ODC. The servers, desktops, networking switches, and equipment used for a specific project should be located in one physical location.
For effective/efficient project execution and to use resources from other projects, you must ensure physical proximity of all the projects for a customer. All projects need to be run from facilities, which are either physically segregated or are within a 20 mile radius of each other.
Non-Disclosure Agreement
All employees should sign a comprehensive non-disclosure agreement before the start of any project. It is the responsibility of the delivery owner and project manager to strictly enforce and monitor the non-disclosure agreement.
BCP Solution
Intrusion Detection System (IDS) will be installed to detect unauthorized access attempts by hackers. The system will serve as an alarm system and the main intention of IDS is to provide a warning that illegal activity is happening or has happened some time back (Crothers, 2003).
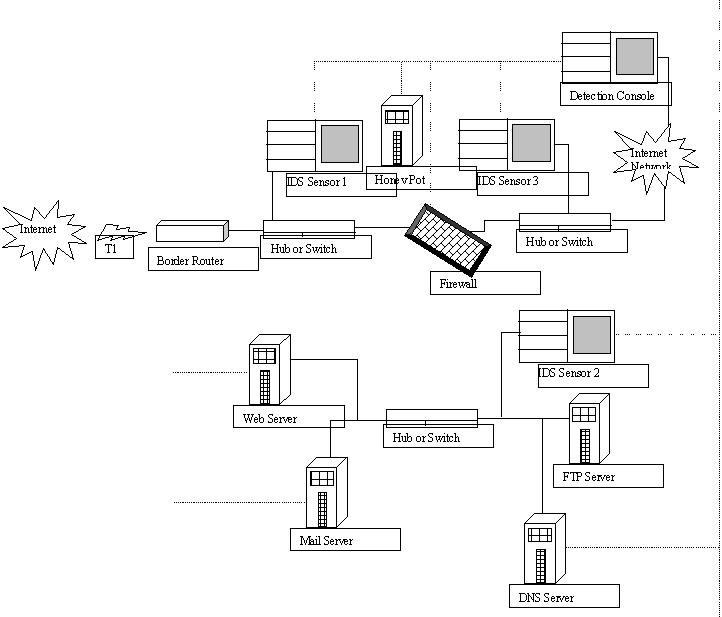
A firewall is used to protect the internal network and create a demilitarised zone and this will isolate the corporate servers from being accessible to the public. There will be three intrusion detection sensors that will monitor the network traffic for signs of attack or malicious activity. The solid lines in the figure are the actual network connections. The dotted lines represent the secure communications that are used to pass detection information from the network and host based intrusion detection sensors to the master detection console. (Crothers, 2003).
Chapter Summary
The chapter has examined the BCP concept and discussed the implementation for three scenarios. BCP is used along with DRP to ensure that after a disaster has occurred and the DRP is implemented, the organisation is able continue its operations. Three scenarios with different types of threats have been examined and they include: hurricane and tornado disasters; when secure lines and VPN networks are compromised and when a network has been severely compromised by hacking or virus exploits. The three scenarios have demonstrated actual implementations of BCP along with network and infrastructure details and networks.
Research Findings and Analysis
As a part of the research activity, an extensive survey was done with IT managers and directors in various companies across the world. A survey instrument was designed and this was emailed to a number of IT managers in various companies. Twelve of the IT managers responded by completing the questionnaire and these people were further interviewed by telephone to get some clarifications. This section presents the research findings and analysis. Please refer to “Table 4.1. Questionnaire used for the Research” that gives the survey instrument. The instrument had 24 questions that queried about the various measures and features of the DRP/ BCP plan implemented in the organisation.
Analysis Questions 1 to 3 – Company Information
Following table gives details of the replies given by the respondents for their organisation. Information given includes name of the company, products and services offered and annual turnover of the company. Currency is in Norwegian Kroner – NOK, US Dollars – USD and Euros:
Table 7.1. Company Information – Questions 1-3.
As seen in the above table, the companies selected vary from the very huge multi national companies such as ExxonMobil with a turnover of 78 billion NOK to smaller companies such as CHC Helikopter Service AS with a turnover of 1.1 NOK Billion. Thus there is sufficient variance in the company profiles and this would allow a better understanding of how IT solutions are implemented in organisations of different sizes, as represented by the turnover.
It can also be seen that the companies selected have different products and services and represent a cross section of various industrial sectors. The industries covered include oil and gas exploration, production, refinery, downstream operations; cellular technology and solutions, electrical energy and power supply; oil drilling contracting services; financial services, seafood; helicopter transportation; banking and pension; industrial gas; aluminium products and renewable energy. So the sample of companies taken are adequate and sufficient variation to represent the DRP and BCP implementation across a wide number of industrial sectors.
The following key is used to represent the companies and each company is represented by a Serial Number such as 1, 2, 3, to 12.
Table 7.2. Company Key Serial Number.
The key serial number representation is used in the future sections of the thesis and would be used to denote responses of different companies for various questions used in the thesis. The number assignment is random and has no bearing in the business or turnover of the companies or their standing in the market. As an example, if we say company 1, then it refers to ExxonMobil, etc.
Effect of disruptions on collaborative business process – Question 4
The answers for this question varied from minor to critical and this depends on the nature of business relation between the organisation and the partners and suppliers. Organisations that have live hosting of back end processing and call centres rated the impact of unexpected downtime as critical while organisations that have periodical drops of software application builds that are deployed in client locations rated this aspect as minor. It must be noted that in the latter case, the company has already implemented DRP and is able to retrieve the source codes at any given point of time.
The nature of collaborative business processes with partners, suppliers and customers needs to be understood first. Suppliers and vendors of products and goods that are linked through the supply chain to the mother nodes and that are located in areas unaffected by a disaster would only suffer loss of communication and connectivity while their physical assets and goods are not harmed in anyway. So when the link and connectivity is broken then at the most, details of work orders, payments, shipments and other such details are lost and these can be reconciled and recovered with some effort.
The case of partners and vendors that perform back office functions such as handling claims, processing payments, extending credit, managing customer banking accounts and credit cards and so on is much more complicated. These organisations process tremendous amounts of information and may process more than a million transactions each day. Any disruption in the service would lead to a blackout and there are chances that transactions in process and waiting for authentication may get corrupted or lost. In such cases, the losses for business and customers would be massive and total.
On the other hand scheduled and planned downtime that are taken periodically are different. In this type of downtime, services are not available for customers and hence transactions are stopped for the duration and there is no input of data and sufficient notice of the downtime is given to the concerned people. Also since maintenance teams and other stakeholders are available at hand, they take proper steps to ensure that data is backed up and nothing is lost. At the most, scheduled downtime can cause a certain amount of inconvenience and while there are lost opportunity costs in the form of customers who tend to go elsewhere, the losses are not extensive and total.
So the impact of a disaster due to downtimes varies from minor to critical and this indicator depends on the nature of the effected business.
Does your company have Disaster Recovery plans – Question 5
The answer to this question was an emphatic Yes from all the organisations that were surveyed. While some organisations already had an advanced DRP in place, others were in the process of implementing the same.
Post 9/11, organisations across the world have realised that disasters, both natural and man made can hit them at any point of time and from anywhere. The past few years also have seen an increase in natural disasters such as earthquakes that hit China, hurricanes that ravaged US and tornadoes and Tsunami. In many cases, these events were not forecast and even when they were forecast, the time gap between the notice and the actual striking of the disaster was too small and with such short notice time, the response time for the DRP to be implemented becomes very short. So a DRP has to be always in place and in a state of constant readiness and it must be possible to launch it with very little notice.
Organisations have moved beyond the wait and watch state where they would watch and see how other organisations that have implemented DRP are able to recover their systems to actual implementations. With the rise in uncertainty of the environment in global operations, with increased acts of terror and also increased fury and unpredictable behaviour of the natural forces, implementing effective DRP has become a need rather than a luxury or an accessory (Toigo, 2005).
The conclusion is that all the surveyed organisations have some form of DRP in place or in an advanced state of implementation.
Cost of protecting business and risk of being unprotected – Question 6
The answer to this question was again an emphatic No. All the organisations did not think that the cost of protecting business against conceivable eventuality is higher than the risk of not protecting at all.
In the fierce competitive environment of today, organisations are at intense pressure to maintain healthy bottom lines and there is an increasing tendency to hive off or close down units that the organisation feels is not profitable or justified in maintaining. A DRP is like a fire extinguisher in the office or in the car. Money has to be paid for the device and it would be used only in the eventuality of a disaster. If it is never used at all or if a fire never occurred at all, then that is really nice but just because a fire has never occurred in the past few years, it would be foolish to question the investment made for the fire extinguisher and attempt to sell it off as a fire can occur at any instant.
To give another example, a DRP is like an accident insurance. People have paid the required insurance premiums for a few decades without ever collecting the money because they were fortunate to have never been involved in an accident. But this does not mean that they should be self-assured in their invincibility and decide to stop paying the insurance payments as accidents and mishaps can occur at any point of time (Wallace, 2005).
IT organisations are particularly notorious for placing employees on the bench when there aren’t enough projects to go around or when they find that there is less demand for people with specific skill sets. There is again an inclination to reduce the employee strength in specific departments that has lesser business and there network security and the DRP teams tend to appear in this list since these functions do not actually generate revenue and are more of support functions. But it is interesting to note that organisations do not regard costs of DRP as more than the cost of the assets they protect (Toigo, 2005).
So the conclusion is that organisations do not think that cost of protecting business against conceivable eventuality is higher than the risk of not protecting at all.
Cost of Downtime and recovery – Question 7
The answer to this question was no. All the organisations surveyed felt that with respect to the cost of downtime, the organisation could not recover easily without an effective DRP in place. Some of the sample answers were “Without effective Disaster Recovery plan in place the organisation cannot recover easily, with out protecting the data it is impossible to recover it , and it is highly risk” and “Its very, very hard to recover after a disaster with out a Disaster Recovery Plan. I feel it is as same as re-developing the system completely from scratch”.
Large projects with team sizes of 100 or more typically take up to 2 years to fully develop a software application test and deliver the final build. This involves hundreds of man-hours and interactions of specialists from other teams who may be involved in trouble shooting certain aspects of the program code. The employee turnover in the IT industry is quite high, of the order of 20% and from the start of a project to the end of a project sees many employees leave and knew members coming in.
If a disaster takes out a location and if there is no DRP implemented, then all the creative efforts of the members is lost forever and the organisation is moved two years back in time. While it may be possible to start development activities from start, this process would probably not replicate the original effort and result in massive drain on resources that the company cannot afford. Besides, there would also be a tremendous loss of goodwill and reputation and confidence of the customers, if it was found that the company did not have a DRP in place.
So the conclusion is that with respect to cost of downtime, organisations do not think that the organisation can recover easily after disaster without effective DRP in place.
Business Impact of Potential Interruptions – Question 8
The question was designed to help respondents to specify the likely impact on the organisation if a disaster strikes. Type of effect possible is low, medium and high. There are two categories of impacts, qualitative and quantitative and each category has a number of possible impacts. For each impact, respondents had to specify the possible effect as L, M or H to indicate Low, Medium or High impact.
Quantitative Impact
The following is the pattern of replies that were given by the respondents for quantitative:
Table 7.3. Quantitative Impact Potential.
The above matrix gives the perceptions of respondents for the possible quantitative impact on business due to interruptions caused by disasters. Quantitative impact refers to the impacts that can be quantified and clearly specified in numbers and values. The answers are analysed as below:
Loss of new Business
The question asked if disruptions would cause a loss of new business. New business typically refers to new accounts that have just been started a mature relation has not yet been developed. It can also refer to potential businesses that the company is speaking with. The answers are:
Low: ExxonMobil, Norske Shell A/S, Seadrill Management AS, Marine Harvest
Medium: Lyse, Statoil Norway ASA, CHC Helikopter Service AS, Yara Praxair AS, Norsk Hydro ASA
High: Netcom, DNBNor, Storebrand ASA:
For the qualiCompanies that rate the impact as Low are very large companies in areas such as oil and exploration and companies like Marine Harvest that is a smaller. These companies have fixed number of clients and new business is relatively slow for such companies. Companies such as ExxonMobil would not attempt to begin new oil field operations every now and then or take up oil exploration contracts every day as such contracts takes months of negotiation. So, companies with lesser new business opportunities and that have fixed number of clients have a low impact on new business, due to disasters.
Contractual penalties and regulatory fines
This indicator refers to the penalties that a company would incur or certain regulatory fines that would be imposed in case the contract obligations are not met. It must be noted that business operate under strict contract terms of delivery and it if any contracts are missed, then the other party has the option of imposing stiff regulations and fines. The breaks up for the replies are:
Low: 4 companies – Netcom, Marine Harvest,
Medium: 3 companies – Lyse, Seadrill Management AS, CHC Helikopter Service AS, Yara Praxair AS, Norsk Hydro ASA
High: 5 companies: ExxonMobil, Norske Shell A/S, Statoil Norway ASA, DNBNor, Storebrand ASA
The inference is that larger companies, particularly in the field of Oil exploration and Banking are under severe contracts and disasters would make them liable for contract penalties and fines. Companies that are in the business of telecommunication and retail are not severely affected by contract penalties.
Lost interest on funds
All the respondents selected Low as the impact for loss of interest on funds. This is primarily because interests calculations are done by other banks and financial institutions that on their own. Even if a disaster was to strike one of the organisations that were surveyed, there is no impact on the interest calculations.
Borrowing expense
The term refers to the expenses that a company undergoes when it has to borrow funds for operating income. Banks and financial institutions often lend money based on a companies asset that are often mortgaged or hedged against the borrowings for security. In the event that a disaster strikes a unit of the company, then there is a possibility that the assets that are mortgaged would be degraded or reduced in value. In such a case, an organization would have to offer additional security and this increases the expenses and in some cases, the interest rate changed by the banks is also increased.
- Low: 2 organizations
- Medium: 5 organizations
- High: 5 organizations
Loss of existing business
The term refers to the conditions where because of a disaster, existing customers would lose their confidence in a company and move their business elsewhere. Only CHC Helikopter Service AS responded that there would be a high impact for loss of existing customers while other companies suggested that the impact of losing existing customers was low. This is mainly due to the fact that temporarily outage of a few days would not make customer move away from a service provider. CHC Helikopter Service AS is in the business of providing helicopter services to oil drill rigs and exploration companies where helicopter is the primary means of transport, especially for offshore rigs or those in very remote locations. Such customers cannot keep their rigs shut off if a vendor cannot provide helicopter services and immediately switch over to a new operator.
Additional compensation paid to counter parties
The term refers to certain contract terms that a company has entered into where an organisation would be required to pay for additional compensation to its partners if it is not able to meet the terms of contract. In such a case, the organization would have to pay some form of compensation. Five organisations indicated that the impact would be low while four indicated that the impact would be medium while three companies indicated that the impact would be high.
Effect on operational capital – value of funds inaccessible
The term refers to the value and performance of assets that is translated into operation value and which would be inaccessible in case of a disaster. When disaster strikes a location, the value of the asset is degraded and it may give reduced performance or it may stop functioning. In such a case, since the asset is not available, the value is reduced or it may not be accessible. Only one company, CHC Helikopter Service AS suggested that the impact would be low while two companies suggested that the impact would be medium while the 9 companies indicated that the impact would be high.
Extraordinary expenses – resources to address disruptions
Nine respondents have selected High as the indicator for extraordinary expenses in the form of resources that would be required to address the disruptions while 3 have selected that the impact would be medium. This means that when companies do face disruptions the amount of effort required to address the disruptions would be huge.
The quantitative business impact analysis was done for a number of factors such as ‘Loss of new business; Contractual penalties and regulatory fines; Lost interest on funds; Borrowing expense; Loss of existing business; Additional compensation paid to counter parties; Effect on operational capital – value of funds inaccessible and Extraordinary expenses – resources to address disruptions. As per the responses 37.5 % showed that the impact would be high, 25 % showed that the impact would be medium while 37.5% said that the impact would be low. The impact perception differed for each factor and depended on the type of industry and service offered. Typically, organisations in oil exploration, banking and financial services, retail felt that the impact would be high for some factors.
Qualitative Impact
The qualitative impact had a number of questions and responses are given as shown in the following table.
Table 7.4. Qualitative Impact Potential.
Detailed analysis of the above qualitative indicators is as explained below:
Cash Flow
Eleven companies indicated that the impact on cash flows would be medium while one company responded that the impact would be low. Cash flow would occur when products and services in a location are blocked and the company would not have any means to access the funds.
Finance reporting and control
Out of the 12 companies, five indicated that there would be a high impact on financial reporting and control while five indicated medium impact and 2 indicated a low impact. In case of a disaster, connectivity with a location is lost along with the financial records and information. Companies such as ExxonMobil and some banking organisations would face severe problems when there is an interruption in the financial system and the damage becomes critical if the information cannot be retrieved and information restored.
Client services – customer perception
This is an important factor as it gives an understanding of what the customer feels about the client services of an organisation. 8 companies said that the impact on customer perception would be high while four said that the impact would be medium. When customers realise that the company or its branch they are dealing with would not be available or out of service, there are feelings of disgust, frustration and for banks and financial institutions, there is a feeling of fear as customers may wonder about the security of their investments and deposits.
Competitive advantage
This factor related to any loss in the competitive advantage position of a company in case of a disaster. While one company said that the impact would high be two said that the impact would be low, the other none companies indicated that the impact would be medium. Companies that operate out of different units usually have some contingency planning with added capacity and it is possible for them to switch production or offer services from the other locations.
Legal or contractual violation
This factor refers to any violations of contracts that the company has entered into with reference to goods or services. Some companies undertake to provide certain services and products as per a contract and if there is any disruption in the flow, then the customer or trading partner can take legal action saying that there was a loss of service. These customers would be depending on an organisation for maintenance of its network and would have thousands of its own customers. When the organisation suffers a disruption, thousands of customers are affected and this can lead to cumulative damage of millions. By implementing DRP and BCP plans, the time lost can be minimised and services restored.
Regulatory requirement
In keeping with government and federal regulations, many companies are required to take regulatory and mandatory measures for protecting the assets. Usually organisations can prove that they have done the needful, when asked by the authorities. All the companies indicated that the impact for this factor would be medium.
Third party relations
The term refers to the business relations that are maintained with other parties and how these relations would be impacted by a disaster. All the companies indicated that the impact would be medium.
Public image
The term refers to the image about the company n the media and the public and what they feel about a company that has lost its data and intellectual property due to a disaster. Seven companies indicated that the impact would be high, four indicated a medium impact while indicated a low impact. Companies such as financial services, petroleum and other such industries often suffer a severe damage in the eyes of the public once it is known that the companies did not institute any DRP and BCP plans and have lost their intellectual property. In some cases, such companies also suffer in the stock market as investors feel that a company that cannot look after its own intellectual property is not safe. Such companies often are the butt of jokes and adverse reporting in the media and in some cases, the damage to the public image lasts for a long time.
Industry Image
The factor refers to the image of the company among its peers in the industry. Out of the 12 respondents, 11 have indicated that the impact would be medium while on company indicated a low impact. Industry groups are more tolerant of their peer companies and the would feel that is such an even can occur at one company, they themselves should verify the status of their DRP and BCP implementations.
Employee morale
The term refers to the morale among the employees of a company in case disaster strikes and the connectivity is gone. Only two companies indicated that the impact would be high while the other 10 indicated a medium impact. Usually, in case of disasters, employees are not retrenched or face job cuts in large organisations and this explains the fact that the impact is not regarded as high.
Work Backlog
The term refers to the work that remains pending in case disaster strikes and employees are not able to do any work. 10 companies indicated that the impact would be high and there would be large volumes of pending work that would have to be cleared along with the ongoing work. Two companies indicated that the impact would be low.
Professional reputation
The term is an extension of the ‘Public Image’ factor and refers to the impact on the professional image of the company as a provider of good service. Customers would develop a very negative image if banks and financial services companies have disasters and are not able to resume operations quickly. In many cases, it would be possible that the company would see an exodus of customers. 10 companies indicated that the impact would be high while two companies selected low as the impact.
Employee turnover
The term refers to employees leaving a company because of a disaster. All the respondents indicated that the impact of such an eventuality would be low and employees would not leave just because of a disaster or because there was a delay in getting the operations online.
The qualitative analysis was done for a number of factors such as Cash Flow, Finance reporting and control, Client services – customer perception, Competitive advantage, Legal or contractual violation, Regulatory requirement, Third party relations, Public image, Industry Image, Employee morale, Work backlog, Professional reputation and Employee turnover. While 15% of the respondents said that the impact would be high, 48% said that the impact would be medium and 15 % said that the impact would be low. So qualitative impacts are substantial in case of disasters.
Central Team or Distributed Team – Question 9
The question had two parts and attempted to find how DRP/ BCP teams are managed. The first part of the question was ‘A: Does your company have a central IT Continuity / Disaster Recovery team?’ and ‘B: have a distributed network of IT Continuity / Disaster Recovery professionals?’. All the companies indicated Yes for both the questions.
The organizations had crises management central team that looked after the overall DRP and BCP plan. The central team was typically made of senior managers and other professionals who looked after the organization wide implementation of DRP and BCP. This team devised all the plans and structure for all locations. The plan included the recovery objectives and time for each location, maximum time within which recovery could be done. To ensure that proper administering of the plan was done at other locations, each location had its own team that was in charge of the maintenance, testing and upgrading the plan. This kind of an arrangement ensures that time is not wasted in running the plan.
Therefore, the inference is that Organizations that operate from multiple locations usually have a central team that is charge of the DRP/ BCP plan and are supported by smaller teams at each location.
RPO and RTO– Question 10
This question asked for references about the RTO and the RPO. The recovery time objective – RTO specifies “the point in time following an operational interruption that a business process and its supporting information system applications must be operations. The recovery point objective – RPO “defines the point in time to which resources such as systems and data must be recovered after an interruption”. As per the discussion of the respondents, each organization had its own RPO and RTO and some common elements are presented in the following table.
Table 7.5. RPO and RTO details.
As seen in the above table, the application streams that are to be recovered are shown along with the RTO and RPO maximum hours and the priority for each is also given. RPO varies from 6 hour maximum to 12 hours maximum while the RTO varies from 12 hours maximum to 24 hours maximum. Some companies had a smaller value for the two times.
RPO is dependant on the organisation goals and requirements and teams need to recover the data as per the priority defined. In some cases, applications may have the same priority and this means that the activity would be conducted simultaneously keeping the RTO in mind. The RPO defines the amount of time the company is ready to accept a loss. If the RPO is 1 hour and the time taken for recovery is 2 hours then this means that the data for 1-hour gap is lost and the organisation must use other means to recover the lost data. RTP represents the time by which the application stream has to be restored.
If this does not happen then the organisation would suffer severe consequences. As seen in the table, the RTO is lesser than the RPO and assumes more importance in the DRP and BCP. Both DRP and BCP would be defined in the business impact and the identified impacts and the priority is given the appropriate importance. Applications to be restored depend on the organisation but they follow the pattern identified above.
The first priority is to restore the key databases as the system cannot operate if the database is not connected. The database would hold all the information and once this is installed and ready, then all other channels are recovered. Operation and process channels along with the financial systems have the same priority since database recovery is followed by these channels. Operation process refer to the core business functions of an organisation so an oil exploration company would first ensure that connectivity to the oil rigs and other units are restored. In some cases, if these systems are not monitored continuously, then can cause explosions and accidents that are more serious.
While operation processes have certain safeguards and shutdown sequences, it cannot be assumed that the failsafe systems would not require monitoring. For banking systems, financial channels may be a part of the operation and process channels and since a couple of companies are from the finance stream, financial systems are given priority 1. There is another parameter and this is the recovery time actual – RTA and this represents the actual time taken as against the specified RTO. Organisations try to reduce the gap between RTA and RTO by conducting regular maintenance and testing. The shorter the gap, the faster the company can meet its objectives.
So it can inferred that Organisations have different priorities for specific application streams that are to be recovered and while the RTO varies between 12 to 24 hours, the RTO varies between 8 to 10 hours.
Frequency of data recovery – Question 11
The question was “Data backup is done at what frequency: Daily/ Weekly/ Monthly/more frequent”. The question attempted to find out how often data backup was undertaken. The answers varied as per specific applications and ranged from daily to weekly and monthly. Banks and other financial institutions, took up back up on a daily basis for the transactions and other details while for reconciliation’s, statements, commissions and other issues, back up was taken on a weekly and monthly basis.
Data backup is very critical for a DRP and BCP and when the plan is being run, teams take the latest build of the backed up data and restore it. If this data is a day old then details of transactions in the previous 24 hours have to be recovered manually. While the argument is to have a backup every few hours, it must be noted that data backup is resource heavy and interrupts business services and slows down the network. One possibility is to increase the connectivity so that more bandwidth is possible but this costs money.
So data backup is usually done at day end and in the night when there are very few employees and customers so that network speed does not effect their business.
Data Storage – Question 12
The question asked was “How do you store data: CDs/ Tapes/ In servers/ Others” and it was designed to understand the method used for data storage while taking back up and also for live data during transaction processing. The answers ranged from CDs, Tapes and in servers.
There are some advantages and disadvantages of storing data in different types of media. While CDs are the most convenient forms and the DVD format allows more than 4 GB of data to be written and integrity of the data is retained, the problem is that data cannot be overwritten on a DVD. Incremental backup method is frequently used for data back up and in this method, data is written once and the next time a backup is to be taken, only data that is changed is written and the remaining data is retained as it. This method ensures that the number of media to be used does not increase with each back up cycle.
The data backup tapes are interchanged by sending data from one location to another. Such practices ensure that in case of fire or destruction of tapes from one location, data on tapes from another location can be used. Tape storage devices would require a special drive with a tape reader and writer and appropriate software to read the information and retrieve it. Small and compact cartridge devices are available with capacities up to 150 GB. Larger devices have compressed capacities of 260 GB or more. Some types and formats of tape drives are QIC, Travan, Digital Audio Tape – DAT, 8mm, Mammoth tape storage, Advanced Intelligent Tape, Digital Linear Tape, Linear Tape Open and these have transfer speeds from 6 to 320 MBps (Snedaker, 2007).
Therefore, the inference is that Organisations use different types of media such as CD and Tape for data backup and these media are periodically interchanged between locations so that if one location is damaged, tape data from another unit can be used.
Volume of Data Storage – Question 13
The question asked was ‘What is the volume of data backed up?’ and the question was designed to find out how much data was included in the periodic back up. The answers ranged from 1 GB to 10 TB – Terra Bytes. One TB is equal to 1000 GB.
This question gives an idea of the magnitude of data to be backed up and recovered during DRP. Such huge volumes of data would prove almost impossible to retrieve manually and highly automated software and tape readers are used that run at speeds of 320 Mega Bytes per second. When such large amount of data is to be decrypted and installed in the database, multiple devices with parallel processing are used and these devices pick up huge chunks of data and decrypt it.
The data back up refers to the total data back up done and since the process in carried out on incremental basis and only data that is changed is written, it is possible that a smaller percentage of data gets written. But the fact remains that this huge amount of data must be backed up and transported to other locations. Failure to take this back up or transfer the tapes to different locations would mean that when a disaster does occur, some part of the date would be lost.
Frequency of Recovery Testing of Backup data – Question 14
The question asked was ‘Do you at regular intervals do recovery testing of backed up data? If Yes then at what frequency?’. All the organisations said Yes that they regularly did undertake recovery of testing backed up data and carrying out other testing procedures. The frequency varied from Quarterly to Yearly.
Decryption and testing to see if the backed up data can be recovered and installed is an expensive process since it requires that a separate system be set up for recovered data to be installed besides requiring manpower and other resources. This is a mandatory process and often is a part of the audit that companies perform on their internal systems. Testing is followed by an analysis to find out problem areas and defects are categorised as minor, major and critical.
Corrective steps and procedures must be implemented and if the same problems are detected in the next test, then the matter is escalated directly to the top management. Organisations view the testing of backed up data very seriously since if this data is corrupted and cannot be recovered, then all the expense and efforts of the DRP/ BCP plan would be a waste.
Therefore, it can be inferred that Organisations take up periodic testing of backed up data that may be quarterly or yearly and carry out audits to ensure that data integrity is not compromised.
Processing Capacity of back up facility – Question 15 – 16
Question 15 was ‘Is the processing capacity of your back-up facility equal to that of your primary facility? Yes / No’. Question 16 was ‘If you answered “No” to Question above, what is the capacity ratio of your back up to your primary facility?’ Question 16 had a number of percentage ranges to indicate the capacity ratio of the back up to the primary facility. The percentage slabs ranged from 1 – 10%; 11 – 20% to 100%.
While 8 companies indicated that, their back up facility was equal to the primary facility, four indicated that the processing capacity ratio of back up facility to the primary facility was not equal. Two companies said that the ratio was between 60 to 70% while another 2 said that the ratio was between 30 to 40 %. Back up facilities are sites that from where DRP teams would attempt to restore the systems.
These sites are usually staggered and placed in different locations and are provided with generator power, emergency phone line, satellite phones and other types of systems. Since such a site would serve as the nerve centre for all back up and restoration facility, it becomes important to ensure that these units have adequate computing power so that the downtime is reduced to a minimum. During the Katrina Hurricane, many financial institutions could quickly recover their data because they had invested in appropriate back up sites. Failure to do so would mean that the DRP would be delayed (FFIEC, 30 July, 2007).
Therefore, the inference is ‘In a majority of the surveyed companies, processing capacity of the back-up facility was equal to that of the primary facility.’
Type of Connectivity – Question 17
The question and the choices were ‘What type of connectivity do you have with the back up sites: ISDN/ Broadband/ Dial Up/ Satellite/ MPLS’? The question was designed to understand the type of connectivity mechanisms used to connect to the back up sites.
All the companies indicated they primarily use MPLS – Multi Protocol Label Switching type of connection and as a further safety, they also have ISDN/ Broadband and even dial up but these other connectivity mechanisms are used for email and other services as a stand by. Some of the companies have even used MPLS to create Virtual Private Networks. MPLS has become the de facto standard for providing secure and high bandwidth connection between organisations and their units. With this type of connectivity, it is possible to obtain connectivity speeds of 40 Gbits/ second and there is no way that a hacker can break into the VPN since only one to one connectivity is allowed.
One of the greatest fears while transferring data is that hackers may gain access to the network and easily download all the information, ready and packed for immediate deployment. By using MPLS, this possibility is removed.
It can be inferred that Organisations use MPLS VPN – Multi Protocol Label Switching Virtual Private Network for connectivity with back up centres and they use ISDN and other connectivity for non-critical applications and mail services.
Specialised software for DRP/ BCP – Question 18
The question asked was ‘Do you use any specialised software for DRP/ BCP? Yes/No’. The question was designed to find out details of any specialised software used in the DRP/ BCP systems.
All the companies selected No when asked if they use any specialised off the shelf software and indicated that they have developed their own system for carrying out the DRP/ BCP implementation and invoking. Third party applications have been used for encryption and decryption.
Since when DRP/ BCP is in place – Question 19
The question asked was ‘Since when is the DRP/ BCP in place and how long did it take to develop?’. Answers for the first part as to when DRP/ BCP was in place varied from 8 years to 10 years. Answer for the second part varied from 6 months to 1 year.
While larger companies had some kind of DRP/ BCP since the past couple of decades, other companies started the implementation post 9/11 attacks when organisations realised that disasters can happen at any time and from anywhere.
Importance of DRP/ BCP – Question 20
The question asked was ‘How would you rate the importance of DRP/ BCP to your organisation’ and choices that were given were ‘Low, Medium, High and Critical. All the respondents selected Critical as the importance they gave to DRP and BCP.
Conclusions
An extensive discussion has been done an extensive examination of DRP and BCP with an emphasis on creating a framework for practical implementation. DRP and BCP implementations would offer protection for the intellectual property of an organisation and help an organisation to quickly recover the soft property in case a disaster strikes. There are four levels of threats and while level 1 refers to a minor outage, a level 4 threats is a major disaster caused by hurricanes and earthquakes.
The thesis has discussed in detail the framework of DRP for an IT company that may operate through multiple locations. A specific organisation chart and steps to be followed for DRP implementation have been presented. To protect the intellectual assets of DRP, a company first needs to have an IT team security structure defined, carry out the risk assessment and perform the business impact analysis.
The next important step is to select the strategy for DRP implementation and form the crises tem management structure and create the process flow to identify disasters and activate the DRP along with the DRP invoking procedure and create project specific disaster recovery plan and the notification procedures. Once the DRP is in place, it is important to create a testing plan and a maintenance plan so that the DRP is in a state of readiness. This chapter is expected to serve as a guideline for organisations and managers who would want to create a DRP for their organisation.
The thesis has examined the BCP concept and discussed the implementation for three scenarios. BCP is used along with DRP to ensure that after a disaster has occurred and the DRP is implemented, the organisation is able continue its operations. Three scenarios with different types of threats have been examined and they include: hurricane and tornado disasters; when secure lines and VPN networks are compromised and when a network has been severely compromised by hacking or virus exploits. The three scenarios have demonstrated actual implementations of BCP along with network and infrastructure details and networks.
As a part of the research activity, 12 companies were contacted and experts in these organisations were requested to complete a questionnaire. The companies selected vary from the very huge multi national companies such as ExxonMobil with a turnover of 78 billion NOK to smaller companies such as CHC Helikopter Service AS with a turnover of 1.1 NOK Billion. Thus there is sufficient variance in the company profiles and this would allow a better understanding of how IT solutions are implemented in organisations of different sizes, as represented by the turnover. It can also be seen that the companies selected have different products and services and represent a cross section of various industrial sectors.
The industries covered include oil and gas exploration, production, refinery, downstream operations; cellular technology and solutions, electrical energy and power supply; oil drilling contracting services; financial services, seafood; helicopter transportation; banking and pension; industrial gas; aluminium products and renewable energy. So the sample of companies taken are adequate and sufficient variation to represent the DRP and BCP implementation across a wide number of industrial sectors.
The questionnaire had 20 questions respondents were asked to complete the instrument and mail it back to the student of this thesis. Answers to the questions were analysed in detail and responses were further segregated to form a pattern. The following conclusions have been arrived at:
The impact of a disaster due to downtimes varies from minor to critical and this indicator depends on the nature of the effected business.
All the surveyed organisations have some form of DRP in place or in an advanced state of implementation.
Organisations do not think that cost of protecting business against conceivable eventuality is higher than the risk of not protecting at all.
With respect to cost of downtime, organisations do not think that the organisation can recover easily after disaster without effective DRP in place.
The quantitative business impact analysis was done for a number of factors such as ‘Loss of new business; Contractual penalties and regulatory fines; Lost interest on funds; Borrowing expense; Loss of existing business; Additional compensation paid to counter parties; Effect on operational capital – value of funds inaccessible and Extraordinary expenses – resources to address disruptions.
As per the responses 37.5 % showed that the impact would be high, 25 % showed that the impact would be medium while 37.5% said that the impact would be low. The impact perception differed for each factor and depended on the type of industry and service offered. Typically, organisations in oil exploration, banking and financial services, retail felt that the impact would be high for some factors.
The qualitative analysis was done for a number of factors such as Cash Flow, Finance reporting and control, Client services – customer perception, Competitive advantage, Legal or contractual violation, Regulatory requirement, Third party relations, Public image, Industry Image, Employee morale, Work backlog, Professional reputation and Employee turnover. While 15% of the respondents said that the impact would be high, 48% said that the impact would be medium and 15 % said that the impact would be low. So qualitative impacts are substantial in case of disasters.
Organizations that operate from multiple locations usually have a central team that is charge of the DRP/ BCP plan and are supported by smaller teams at each location.
Organisations have different priorities for specific application streams that are to be recovered and while the RTO varies between 12 to 24 hours, the RTO varies between 8 to 10 hours.
Data backup is usually done at day end and in the night when there are very few employees and customers so that network speed does not effect their business.
Organisations use different types of media such as CD and Tape for data backup and these media are periodically interchanged between locations so that if one location is damaged, tape data from another unit can be used.
Volume of data back up varies from 1 GB to 10 TB.
Organisations take up periodic testing of backed up data that may be quarterly or yearly and carry out audits to ensure that data integrity is not compromised.
In a majority of the surveyed companies, processing capacity of the back-up facility was equal to that of the primary facility.
Organisations use MPLS VPN – Multi Protocol Label Switching Virtual Private Network for connectivity with back up centres and they use ISDN and other connectivity for non-critical applications and mail services.
All the companies selected No when asked if they use any specialised off the shelf software and indicated that they have developed their own system for carrying out the DRP/ BCP implementation and invoking. Third party applications have been used for encryption and decryption.
While larger companies had some kind of DRP/ BCP since the past couple of decades, other companies started the implementation post 9/11 attacks when organisations realised that disasters can happen at any time and from anywhere.
All the respondents selected Critical as the importance they gave to DRP and BCP.
Limitations of Research
While the framework and network architecture and implementation steps for DRP are obtained from interviews and surveys, an actual DRP exercise when a disaster has struck a location ha not been performed. This is important to gauge the effectiveness and speed with which DRP and BCP can be effected.
Recommendations for further research
It is recommended that to provide a focussed research, a very detailed study of the actual DRP and BCP implementations should be conducted for different industry sectors. It is also recommended that a live analysis to gauge the response speed and effectiveness when an actual disaster has struck should be examined.
References
Ann, G.. 2001, A Framework for Disaster Recovery Planner’, 2001, Disaster Recovery Planning- Process and Options white papers, Comprehensive solutions, Brookfield, USA.
Ambs Ken. 2000. Optimising restoration capacity in the AT&T network. Interfaces Journal. Volume 30. Issue 1. pp: 26-40.
Amble, B. 2004, ‘SMEs booming in UK PLC’, Management-Issues. Web.
Benton, Dick. 2007. Disaster Recovery: A Pragmatist’s Viewpoint. Disaster Recovery Journal.
Botha Jacques. Rossouw Von Solms. 2004. A cyclic approach to business continuity planning. Journal of Information Management & Computer Security. Volume 12. Issue 4. pp. 38-51.
Broder James F. 2002. Risk Analysis and the Security Survey, 2nd edition. Broder. Boston, MA: Elsevier Science. ISBN: 0750670894.
Brunetto Guy. 2006. Disaster recovery: How will your company survive? Journal of Strategic Finance. Volume 82. Issue 9. pp: 57-62.
‘Beyond disaster recovery: becoming a resilient business’, 2007, IBM Global services, USA.
Byrne David. 2002. Interpreting Quantitative Data. Sage Publications Ltd; 1 edition. ISBN-13: 9780761962625.
‘Consulting Methodologies- Disaster Recovery Planning’, 2003, Info Tech Research. Web.
Crothers Tim, 2003. Implementing Intrusion Detection Systems. Wiley Publishing Inc. ISBN 8126503688.
Edwards Frances L. 2006. Businesses Prepare Their Employees for Disaster Recovery. Journal of Public Manager. Volume. 35, Issue. 4; pp. 7-13.
Denzin, Norman K. & Lincoln, Yvonna S. (Eds.) 2000. Handbook of Qualitative Research. Thousand Oaks, CA: Sage Facer Dave. Rethinking: Business continuity. Journal of Risk Management. Volume 46. Issue 10. pp: 17-21.
FFIEC. 2007. Lessons Learned From Hurricane Katrina: Preparing Your Institution for a Catastrophic Event. Web.
‘Finding the right disaster recovery balance’, 2006, Computer Weekly. Web.
Fitzgerald Kevin J. 1995. Establishing an effective continuity strategy. Journal of Information Management & Computer Security. Volume 3. Issue 3. pp: 105- 138.
Freiman, J.A., T.C. Chalmers, H. Smith et al. 1978. The importance of beta, the type II error and sample size in the design and interpretation of the randomized control trial. New England Journal of Medicine 299:690-694.
Gilchrist Bruce. 2001. Coping with Catastrophe: Implications to Information Systems Design. Journal of the American Society for Information Science. pp: 271-278.
Greg, S. 2007, ‘Disaster Recovery Planning for SMBs’, Computer weekly. Web.
Gottfried, I.S., 1989, When disaster strikes”, Journal of Information Systems Management, pp. 86-9.
Hiatt Charlotte J. 2007. A Primer for Disaster Recovery Planning in an IT Environment, 2nd Edition. ISBN-10: 1878289810.
IDC. 2007. Indian IT Industry Growth Statistics. Web.
Lavell Joan L. 2004. Business continuity plans: An overview. Journal of Investment Compliance. Volume 5. Issue: 2. pp: 75-86.
‘Survey shows holes in UK’s corporate disaster recovery plans’, 2008, Business Management Zone News. Web.
Kakoli, B. and Peter, P.M., 1999, ‘A framework for integrated risk management in information technology’, Management Decisions, Vol. 37, No. 5, pp. 437-444.
Kaye David, Graham Julia. 2006. A Risk Management Approach to Business Continuity: Aligning Business Continuity with Corporate Governance. Rothstein Associates Inc. ISBN 1-931332-36-3.
Liz, G. 2007, ‘Disaster Recovery’, accounting today journal, Vol. 21, No. 7.
Maiwald Eric. 2002. Security Planning and Disaster Recovery, 1 edition. McGraw-Hill Osborne Media.
Margaret Pember. 2007. Information disaster planning: An integral component of corporate risk management. ARMA Records Management Quarterly. Volume 30. Issue 2. pp: 31-39.
Margulies Stuart. 2006. Preparation for the DRP test: (Degrees of reading power), 2nd Edition. Educational Design publications. ISBN-13: 978-0876942857.
Meade Peter. 1993. Taking the risk out of disaster recovery services. Journal of Risk Management. Volume 40. Issue 2. pp: 20-26.
Mick Savage. 2002. Business continuity planning. Journal of Work Study. Volume 51. Issue 5. pp. 95-123.
Moore Pat. 1995. Critical elements of a disaster recovery and business/service continuity plan. Journal of Facilities. Volume 13. Issue 9/10. pp: 195-236.
Potter Chris. 2003. New survey raises serious concerns about the effectiveness of disaster recovery plans. M2 Presswire.
Preston W. Curtis. 1999. UNIX Backup and Recovery. O’Reilly Media, Inc. ISBN-10: 1565926420.
Presswire. 2008. Price Waterhouse Coopers. New survey raises serious concerns about the effectiveness of disaster recovery plans. M2 Presswire. pp: 2-3.
Pfleeger Charles P. 2002. Security in Computing, 3rd Edition. Prentice Hall PTR. ISBN-13: 978-0130355485.
Questionnaire. 2007. Vendor Resiliency Business Continuity Planning Questionnaire. Web.
Snedaker Susan. 2007. Business Continuity and Disaster Recovery Planning for IT Professionals, 1 edition. Syngress Publications.
Silverman David. 2001. Interpreting Qualitative Data: Methods for Analysing Talk, Text and Interaction, Second edition. Sage Publications. ISBN 0761968652.
Swartz Nikki. 2004. Survey Assesses the State of Information Security Worldwide. Information Management Journal. Volume 38. Issue 1. pp: 16-20.
Toigo, J.W., 1992, Disaster Recovery Planning: Managing Risk and Catastrophe in Information Systems, Yourdan Press Computing Services, Prentice-Hall, Englewood Cliffs.
Toigo Jon William. 2002. Disaster Recovery Planning: Preparing for the Unthinkable, 3rd edition. Prentice Hall PTR.
Toigo Jon William. 2005. Disaster Recovery Planning: For Computers and Communication Resources. Wiley; Publications. ISBN-10: 0471121754.
Varghese and Mathew, 2002, ‘Disaster Recovery ‘, Course Technology publication, pp. 11-15.
Varghese Mathew. 2002. Disaster Recovery Planning, 1 edition. Muska & Lipman/Premier-Trade.
Wallace Michael, Webber Lawrence. 2004. The Disaster Recovery Handbook: A Step-by-Step Plan to Ensure Business Continuity and Protect Vital Operations, Facilities, and Assets. AMACOM.
Winkworth, G., 2007, ‘Disaster Recovery : A review of the literature’. Web.